Hello,
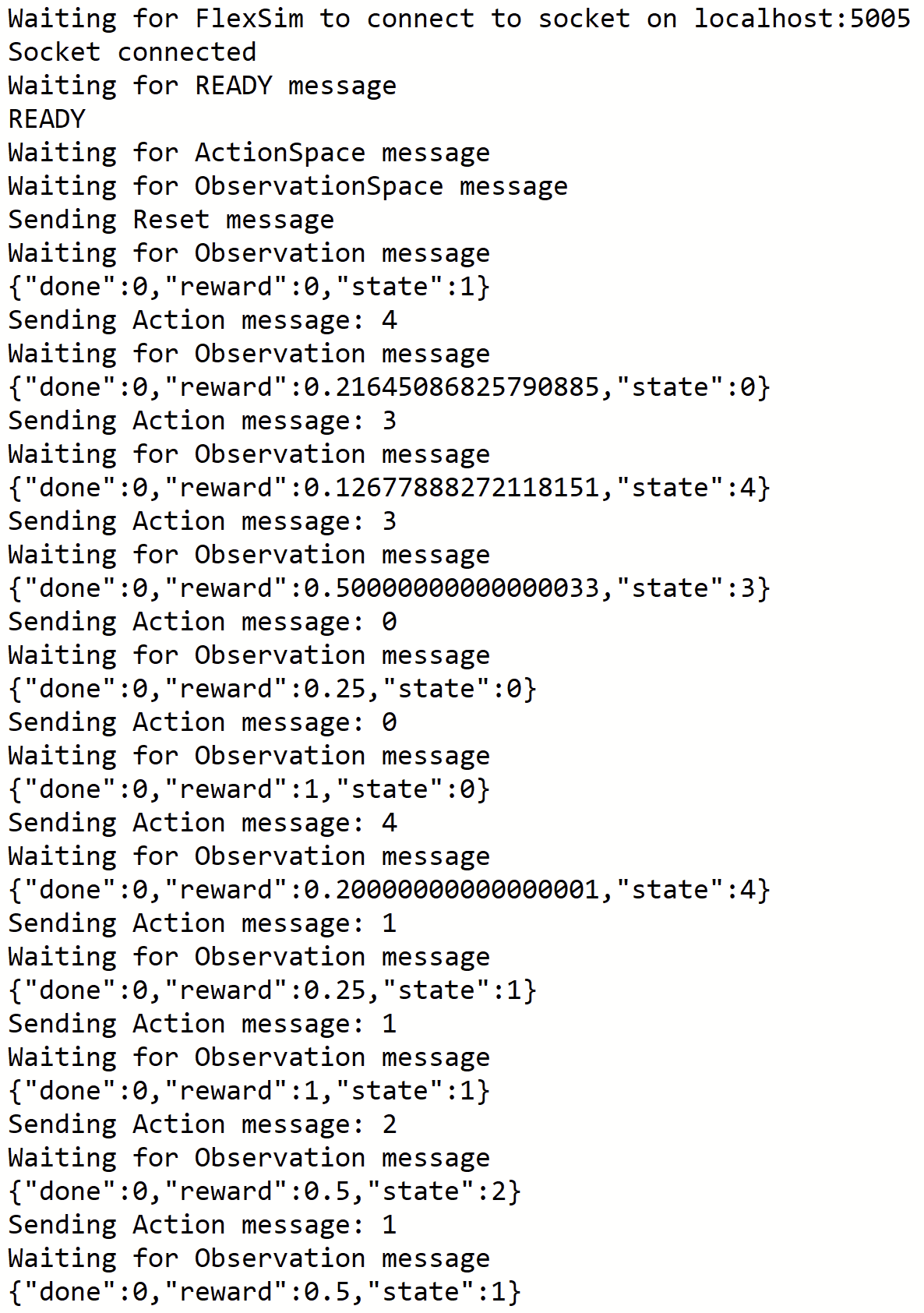
I’ve been following this tutorial: https://docs.flexsim.com/en/22.1/ModelLogic/ReinforcementLearning/Training/Training.html und have successfully implemented and run the two Python scripts, flexsim_env.py and flexsim_training.py. However, I have trouble understanding parts of the output. I've attached a screenshot for reference.
1) In the FlexSim model, the "action" and "observation" parameters ("LastItemType“ and "ItemType“) are defined to have values between 1 and 5. However, in the output, the state values range from 0 to 4. Why is there this discrepancy between the expected state range in the model and the observed state values in the output?
2) At the beginning of each iteration, the "state" values from the Action and Observation messages don’t match. After a few simulation steps, the values do align, but why are they initially inconsistent?
Thank you!