Hello all,
Regarding the last translation method offered since V21.2, I have some question about the .csv and the method itself:
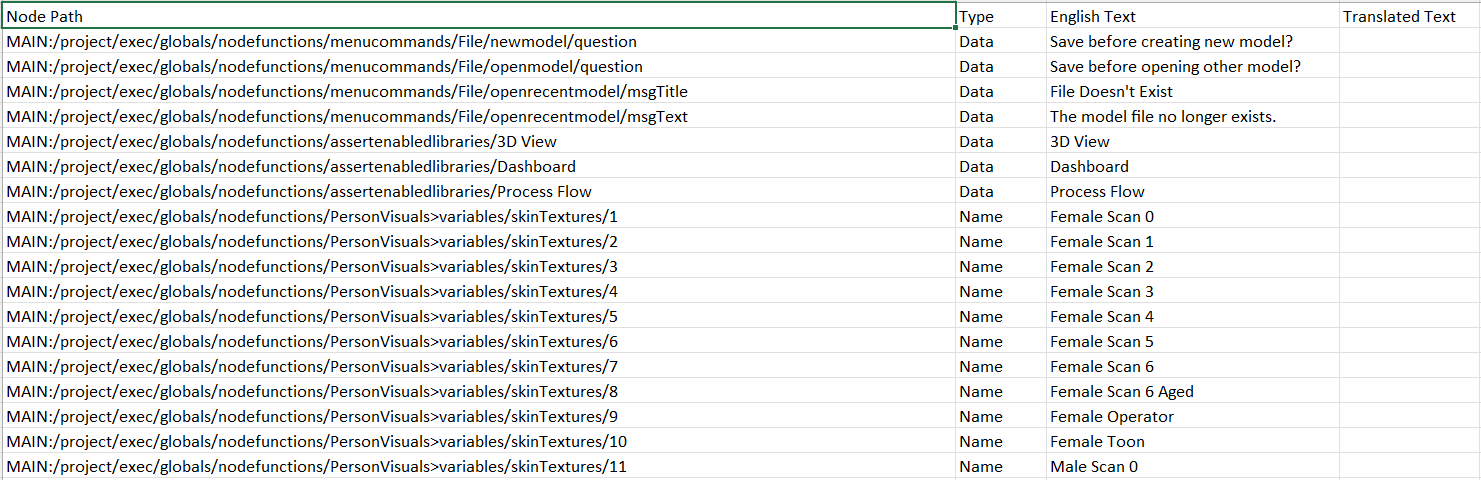
1. As I opened the original .csv in english, I find some rows of the document in this way:

Where the mark is in green is where the 3rd column started showing the original English-language text used for that node. My guess is that, the text where the yellow mark is is the continuation of the english text for that node. I've found this in several other nodes. What I've been doing is copy the text marked in yellow (placed in column A) and paste it after the other text marked in green (column C), however, I have my doubts about it.
¿Is that the right thing to do or is there a reason why there is that text in the first column and that blank row?
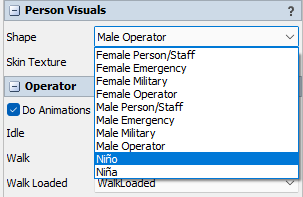
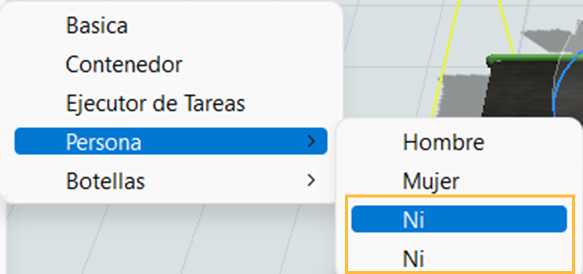
2. Some languages like spanish have letters such as ñ or words with accents that are write above the letter. Since the document is encoded in UTF-8, how could I manage to write translated words that has this words with the special characters described in the documentation?
3. For text like this:

Is it recommended to keep the text in quotation marks exactly the same? I've realized this show the icon on the left of some window. Should I keep it without space between the text in quotation marks and the translated text?
4. So far I haven't found the nodes for these splitter panes:

I hadn't been able to found a node like this one:
VIEW:/active/MainPanel/BackPanel/SplitterXPane/ToolTabPane/TabControl/LibraryIconGrid/GroupIconGrid>viewfocus/Fixed Resources
I don't know whether this is my mistake or is one of the potential missing nodes in the .csv
Thank you in advance and I would appreciate any other recommendations about his besides the ones given in the documentation.