FlexSim 2022 introduced a Reinforcement Learning tool that enables you to configure your model to be used as an environment for reinforcement learning algorithms.
That tool makes connecting to FlexSim from a reinforcement learning algorithm easier, but that tool is not absolutely necessary for this type of connectivity. The same socket communication protocols that are used by that tool are available generally in FlexScript.
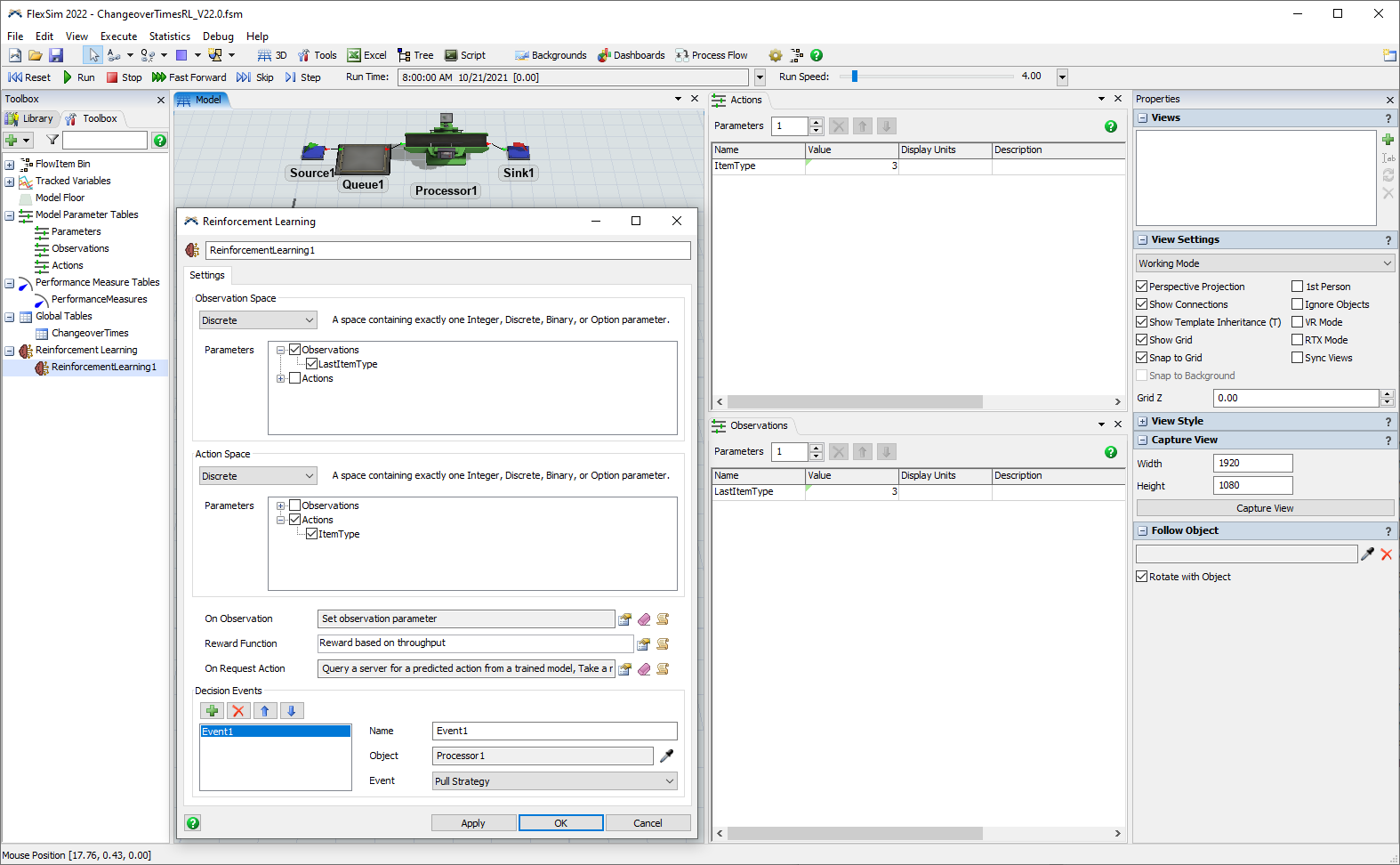
Attached (ChangeoverTimesRL_V22.0.fsm) is the FlexSim 2022 model that you build as part of the Using Reinforcement Learning documentation that walks you through the process of building and preparing a FlexSim model for reinforcement learning, training an agent within that model environment, evaluating the performance of the trained reinforcement learning model, and using that trained model in a real production environment.
Also attached (ChangeoverTimesRL_V6.0.fsm) is a model built with FlexSim 6.0.2 from 2012 that does the exact same thing, but with custom FlexScript user commands instead of the Reinforcement Learning tool. You can use this model with the example python scripts and FlexSim 6.0.2 in the same way that you can use the other model with those same scripts in FlexSim 2022.
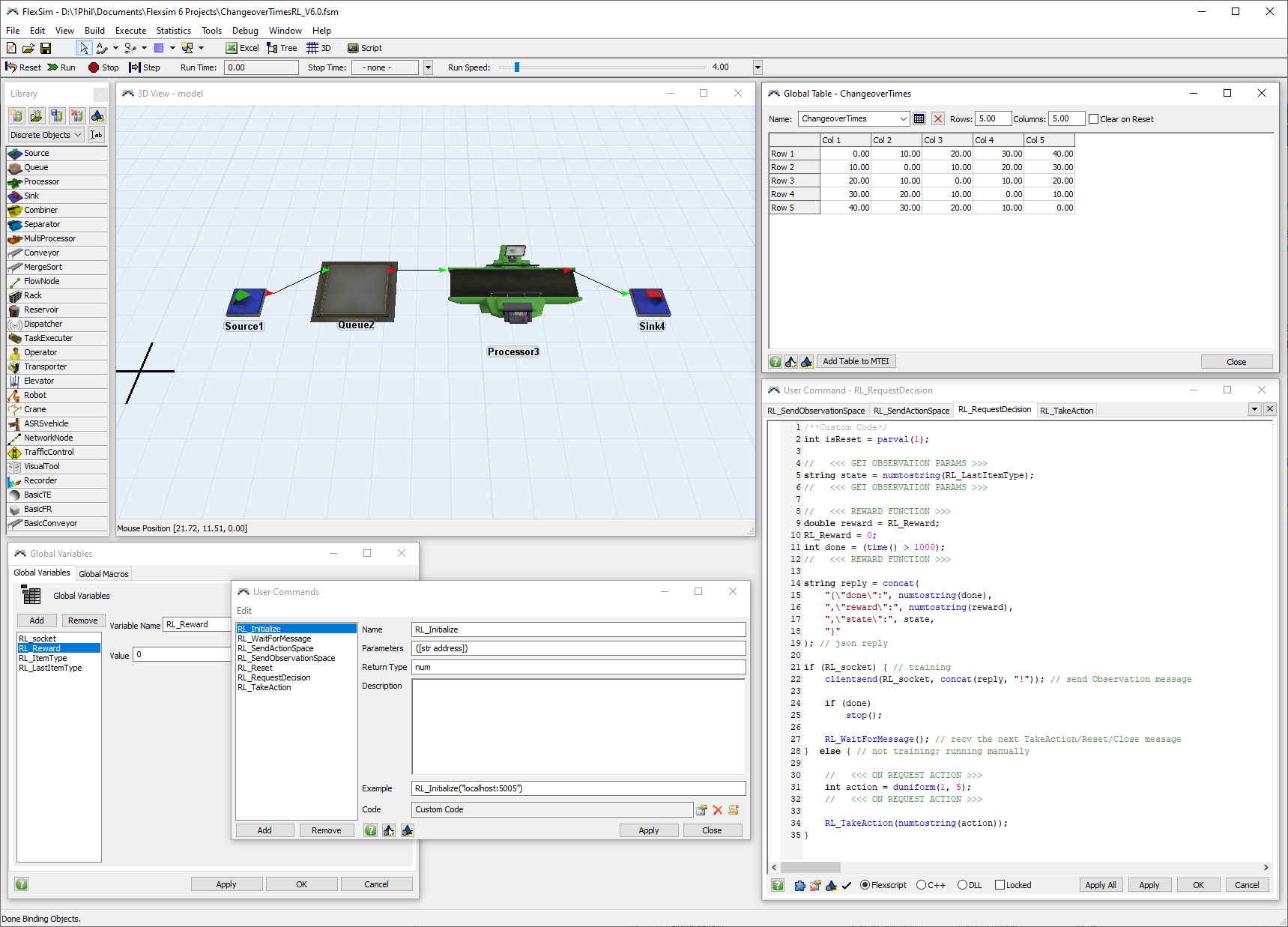
I'm providing this FlexSim 6 model as an example that demonstrates how you can communicate between FlexSim and other programs. The Reinforcement Learning tool certainly makes this type of communication easier and simpler, with a nice UI for specifying RL-specific parameters, but the fundamental principles of how this works have been available in FlexSim for many years using FlexScript.
Hopefully this example can help teach and inspire those who wish to control or communicate with FlexSim from external sources for purposes other than just reinforcement learning. FlexSim is flexible, and the possibilities are endless.
