
This small model shows how to batch various parts together to form 'valid' combinations as they become available. This differs from a regular combiner where the component quantities are set in advance of the components being accepted in the combiner (often based on the type of item on port 1 entry). The valid combinations are shown as the quantities required for a number of products in a global table "ProductPartQuantitiesGrid":
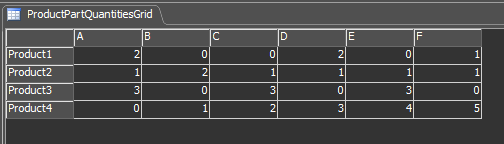
By referencing the first picture and this table, you may be able to see that the model first constructs 4x Product2 followed by one product1 and a Product3. In the background process we are creating a token for each product which is then trying to pull all the parts needed while competing with the other products. This part of the process could be constrained in some way, for example where there is a target for the number of each product to produce over a time period.
So these tokens are being created in the Object Process Flow of the object we're calling OpportunityCombiner at time zero based on the table shown above:
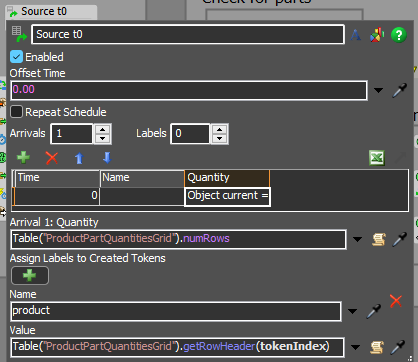
Instead of the normal array generation this model creates a table label of the required parts for a product and stores it on the token. For Product1 that looks like this:
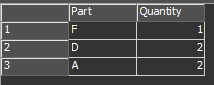
Tables aren't quite fully supported as labels yet so the syntax is a little odd when using them - in this case we do it like this:
- Table(token.partsTable)[1]["Part"] // evaluates to 'F'
Setting the labels up so that syntax works is a bit more complex. Note that the partsTable label is actually a pointer to the data table label on the token - called partsTableData. To get the view shown above you need to right click on the label partsTabelData and select "Explore As Table". Hopefully in the future this may be more streamlined if more people start using labels as tables.
The grid table doesn't play nice with sql, so another table creates itself at reset with a structure that is sql friendly:
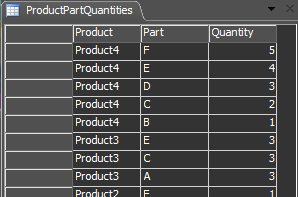
That means the label table can be created with this query:
- SELECT Part,Quantity FROM ProductPartQuantities WHERE Product=$1.product
What remains for the product token just involves getting the parts (a subflow) and them moving the array of all items to the combiner (a queue in the example); stacking them together and releasing to the conveyor before looping back to try and produce another. Below you see the main flow with four tokens - one for each product defined in the grid.
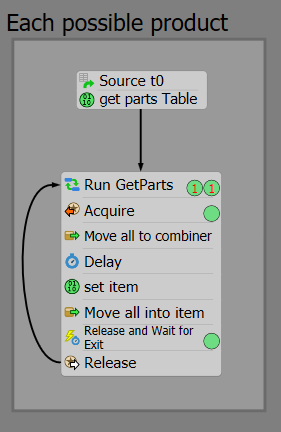
The subflow to get parts reads the token's table of parts for its product, and tries to get the correct quantities for each. This is similar to @Jordan Johnson 's solution for pulling from multiple lists, but is instead considering the table of parts from one list rather than arrays of resource lists and quantities.
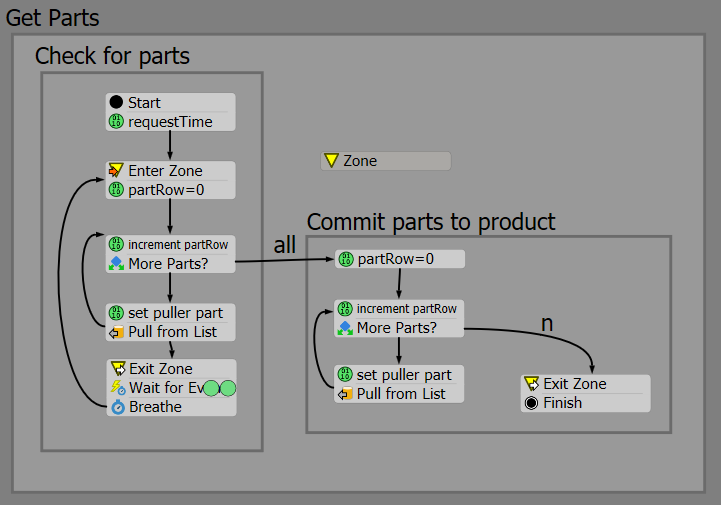
The key aspects of this flow are that
- 1. the first loop in the check section leaves the parts on the list, while the 'commit' section removes them
- 2. we exit the check loop by using the pull timeout when we fail to pull the required quantity of a part type
- 3. those that fail listen for pushes to the parts list
- 4. success full product pulls insert the items pulled to the tokens label 'allItems' for later use.
Attached is the model. It should be relatively simple to transfer the process and tables to another model.
