Hi,
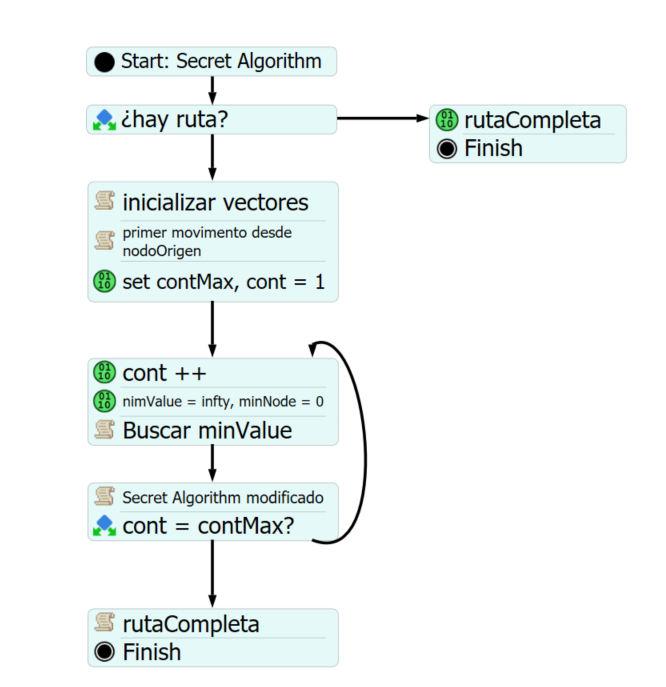
I developed an algorithm using a custom code in process flow. Then, I expanded the same algorithm using several process flow activities and I compared processing times using performance profiler for both.
The conclusion was that when I used expanded algorithm the processing time was shorter than the case were i was using a single custom code.
¿Can anyone explain me why this is happening?
Thanks in advance.
Custom Code algorithm:

Expanded algorithm: