My current model is as follows I want my reinforcement learning to learn to have the best policy when I pull the goods
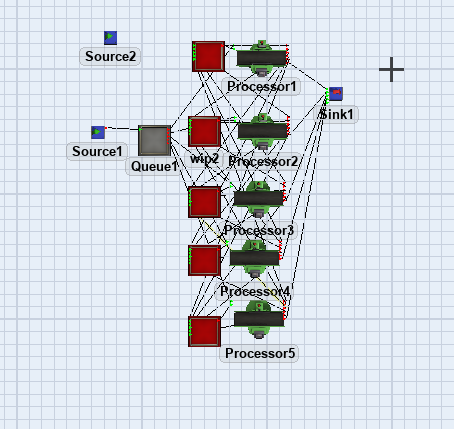
Then I am currently using the odd-job processing. The red part in front is the wip area. What I want to do is to use reinforcement learning to find the best arrangement. How do I adjust and do I need to adjust my reward funtion?0816-2-1.fsm
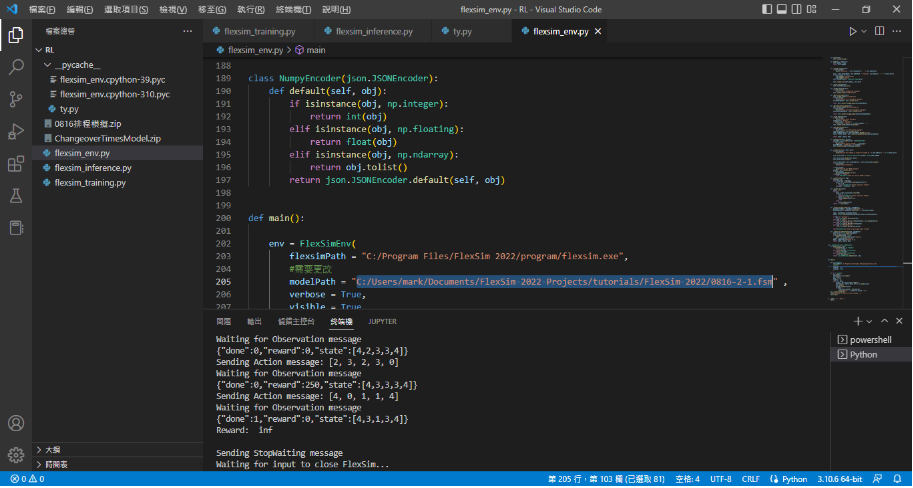
And why are my results like this? I did it wrong
{kind=link}