Now I have a zero-type production model, my problem is as follows, I don't know how to set up my reinforcement learning, do I have to set up three reinforcement learning tools? And after I read the literature, I think To know my average process time how can I setrlmodel.fsm
Reinforcement Learning
FlexSim 22.0.0
@mark zhen, please provide more details about the problem you're facing. What is a "zero-type production model"? To me, that seems like all items are the same, but in the model you posted, there's a Global Table with
different types of flowitems. What literature are you referring to? Do you understand the
concepts found in the documentation? We are happy to help you with FlexSim related questions, but we can't help you much with Reinforcement Learning specific questions.
The model is the production of a job shop, and I want to set the reward function to be smaller and smaller in total completion time. Then how do I adjust or set the function settings.
I have updated a smaller production model and my problem is still the same I want to explore how to set up a larger throughput (aka minimum processing time), my current model has a little problem but I don't Know how to adjust.rlmodel_autosave.fsm
Hey @mark zhen, I found where your problem is coming from. The variable "f_lastlabelval" is only set in the Processor -> Setup Time if you're using the Using From/To Lookup Table ( "tablename" ) option. So when your rewards function goes to u se that variable, it is null. Then it tries to set the Parameter "LastItemType" to null (or 0), but it can't because the lower bound is 1.
Hey @mark zhen, I think I was able to understand what you were looking for and made a sample model based off what you provided. I'll explain the parts.
I started by removing two of your three RL tools. You only need one. You can think of an RL tool as a brain. You don't need three different brains to figure out these three different scenarios; you want one brain that can optimize throughput in this system. Here's what's different.
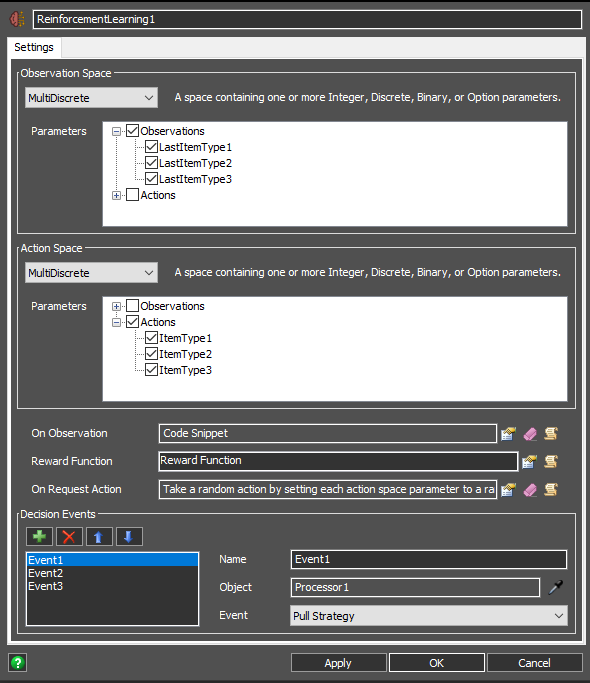
I started by making your Observation and Action spaces MultiDiscrete. That means that you can use multiple different parameters, each for a different Processor you have. I changed the On Observation trigger to only update the LastItemTypeX parameter for whichever processor last released an item. I updated the Reward Function to count the total number of items that have passed through to determine when the run was done, rather than a time-based thing. I chose this because you have a finite number of items coming through the system, so the end-times varied thus leaving the connection to the python script hanging. I made one decision event for each of the Processors when they decided to pull.
In the model, I changed some of the logic. I moved the label setting to a Process Flow to keep the updating process simpler.

I added a Pull Requirement to the Processors so the would only pull items whose type and step match the "StationAssignments" table (renamed from "GlobalTable1" to be more descriptive). 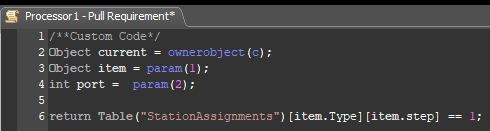
When I run it with the flexsim_env.py script, I get different Actions and rewards through the different runs. The reward function isn't optimized - I left it as the default one from the tutorial. You'll have to figure out what a good reward function is for your system so that it incentivizes your system to pick the right types of items.
Hope this helps.
I think the order I provided is just an example it could be an exponential distribution or some other form of random distribution so how do I tune the model and my reward function and I have other ideas like say I want to keep track of my replacement time, But I don't know how to design my observation space and reward function.
Please be specific when asking questions. Which parts of code would you like me to explain? You say you don't know how to design your observation space and reward function - what don't you understand about it? Do you know the concepts of RL? Have you done other RL projects outside of FlexSim (i.e., in Python or other coding languages)?
15 People are following this question.