Hi,
I'm working on a reinforcement learning project. The basis is that of the reinforcement learning tutorial.
In the model I added a second source and a second queue so I have one source which generates 5 types of pallet and another one which generates 5 types of people. What I want is apply reinforcement learning, to maximize the occupancy of the pallets (25 places), taking from the second queue, the same type of people of the pallet that is getting processed.
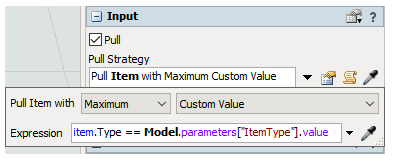
As in the reinforcement learning tutorial, I wrote an input pull strategy in the processor, because without the python's code provided doesn't work. In the pull strategy I say to take the type that has more people in the queue than the others. The problem is that I think that the model doesn't learn, but follows only the pull strategy. I want that the model learn to do this, not that someone tell it what to do, can you help me with what I want?
Probably I have also problems with the settings of the parameters in the observation space.
I attach the model.