Hi,
I would like to ask you about the sqlite file.
An sqlite file is created when performing optimization, but as shown in the image below, even if multiple optimization jobs are created, the sqlite file appears to be shared. Is this understanding correct?
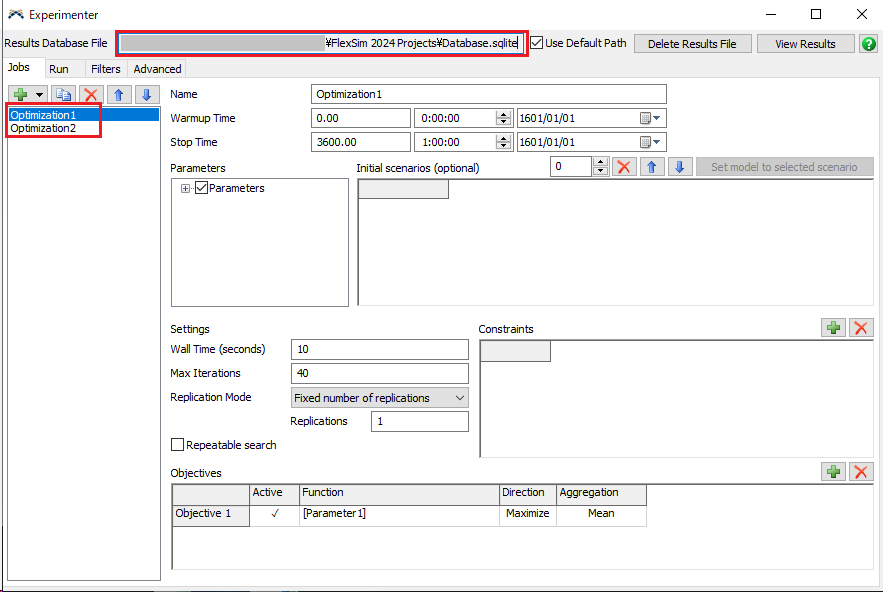
If correct, are you referring to this sqlite file even if you have set different conditions in each job? I feel that the correct data may not be accumulated depending on the situation.What do you think?
