Hello,
I have my own model where I created 2 decision events - one for each queue. But there is no window to set the On Observation, Reward Function or on Request Action trigger individually (differently) for each Decision Event. Therefor I have set parameters for both queues at once there. RL training works like this. I tried to delete the second decision event and it works also, because the action parameters for the 2nd queue are set already by running the Decision Event 1.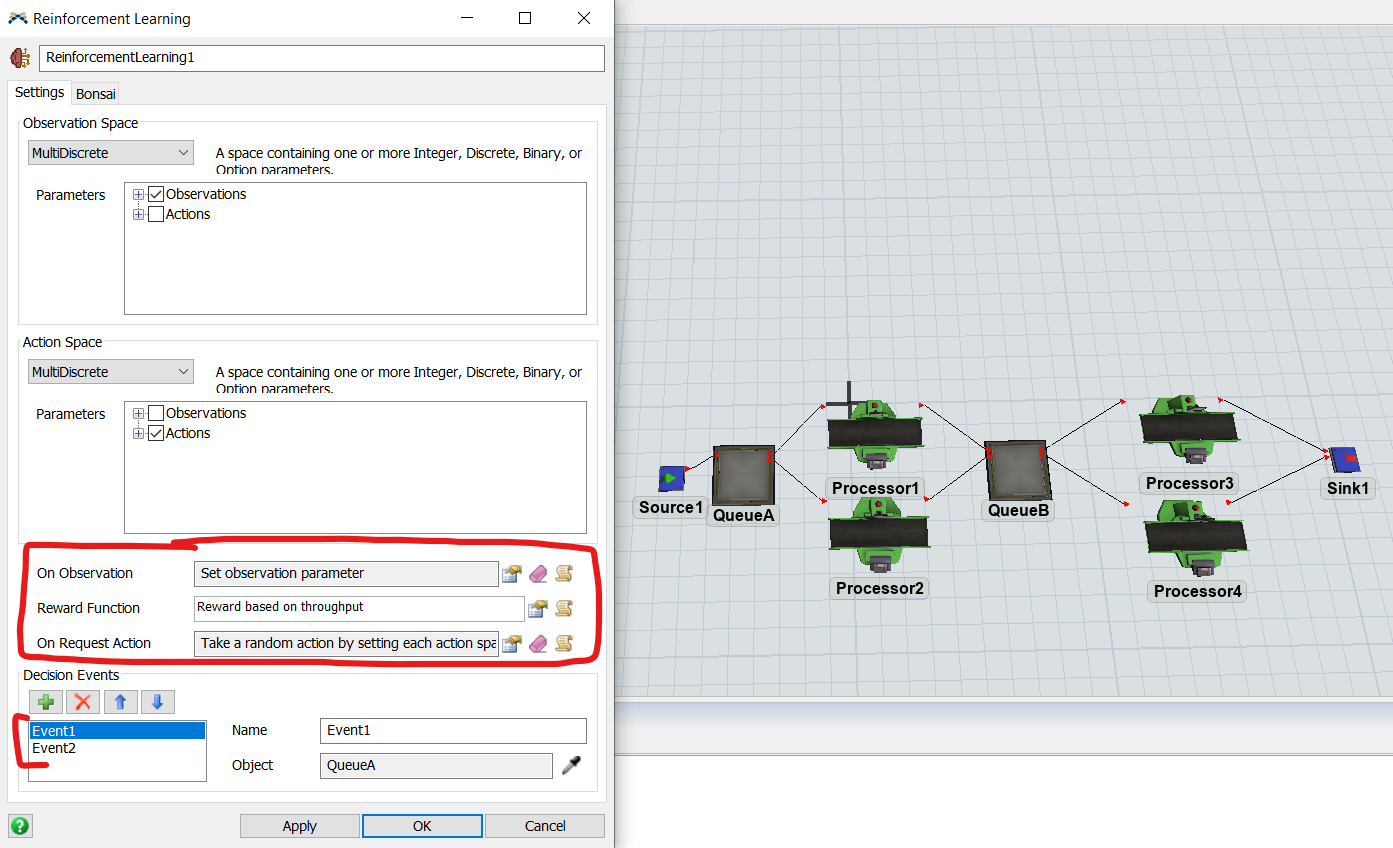
2 Decision Events: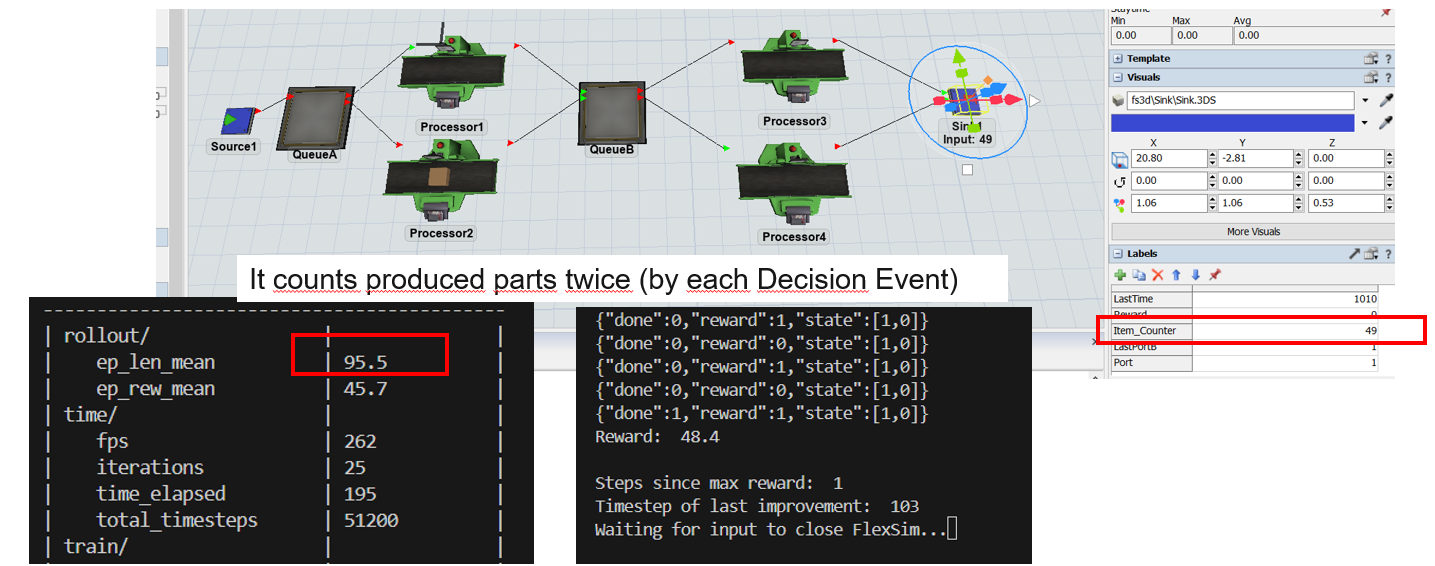
1 Decision Event - seems to be more correct:
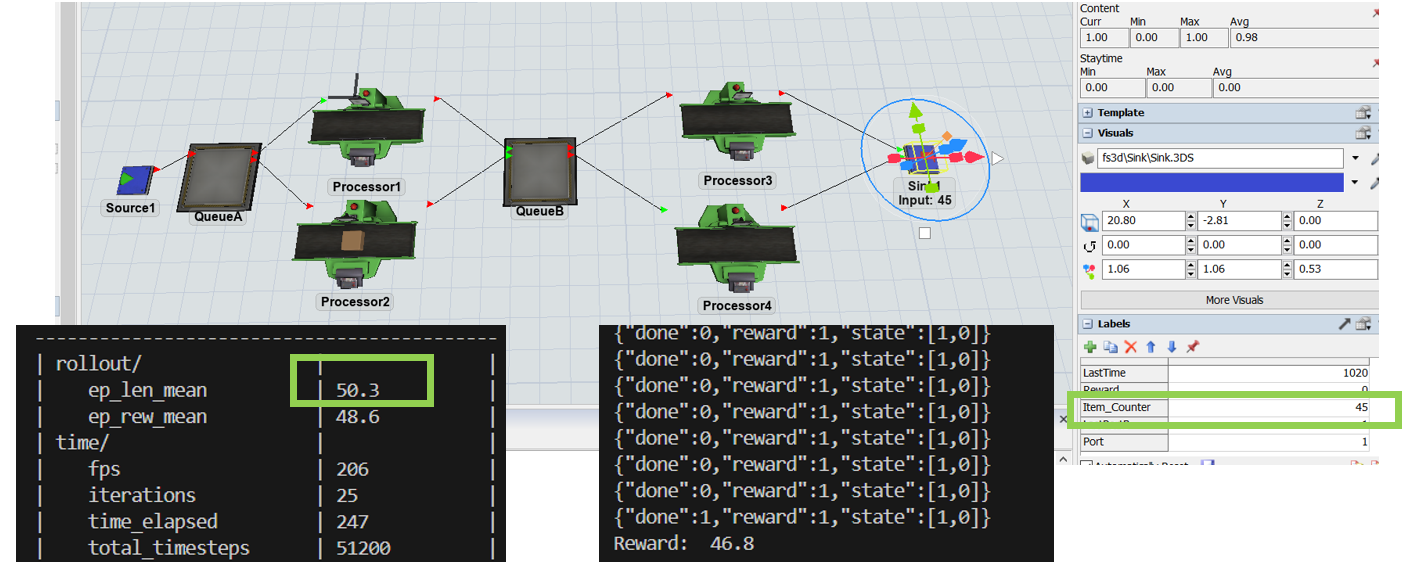
Is it correct to use only one Decision event in this model? In which case is it necessary to use more Decision Events? Why cannot be triggers set individually for various Decision Events?
Thank you in advance :-)