I have a simulation model that builds widgets, which are composed of many sub-assemblies. We have varying numbers of each sub-assembly in stock at the beginning of the year, when the model is started, and more of these sub-assemblies are built as the model runs. With approximately 27000 sub-assemblies at the start of the model, spread over 100 different types of sub-assemblies, the model takes about 30 seconds before it will even start (solely due to this initial quantity source) because of how much is going on at time 0. What is a more efficient way to handle this? The entities are all created in a single source and are assigned labels with the item name and part number. The entities are sent to queues where they wait until a combiner pulls them in.

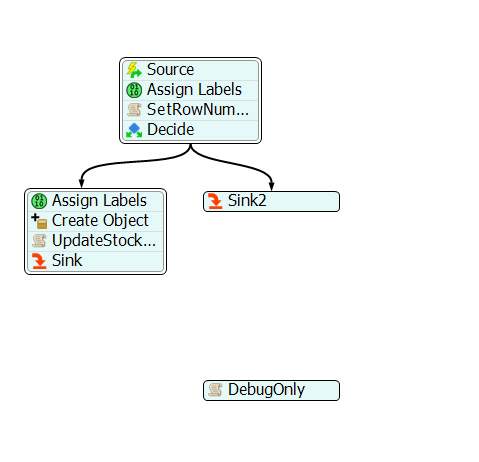
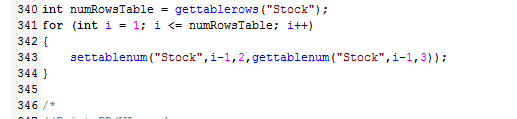
If you're creating 27,000 flowitems and then setting labels on each one, there isn't a whole lot that can be done to improve performance except to buy a faster computer. You may want to think about changing your model so you don't have to create so many flowitems at the same time, or ever.
I'm not sure what kind of system you're building, but one example would be a warehouse picking model. When you're dealing with parts picking, especially small parts, a warehouse may have thousands or hundreds of thousands of different parts. Creating a flowitem for each of these is unreasonable. Instead, all of the data for all of the parts would be stored in a global table and then flowitems are created for each part 'on demand'. This way, you only have a handful of flowitems in the model at any given time.
You may be able to make each flowitem represent multiple objects.
If you don't need a 3D oject for each of the 27,000 sub-assemblies, a token in Process Flow is much smaller with a lot less overhead than a flowitem. Creating 27,000 tokens is almost instantaneous.
Hopefully one of these options helps or gives you an idea of how to improve your model's performance.
7 People are following this question.

{kind=link}
{kind=link}
{kind=link}