Hello,
I have a problem with calculating the waiting time (stay time).
Short introduction of the model :
There is one work station that processes 3 types of products (A-red,B-green,C-yellow) arriving with a certain empirical distribution. Every order has different processing times (job shop). Every once in a while the work station also processes spare parts (blue). The machine and operator follows a 1 shift time table from 6 am to 2 pm for 5 days a week (the order arrival has already excluded weekends). The simulation is run for 3 years from 2017 to 2019.
There are 3 main KPIs to be measured (Dashboard) : Lead Time of Product A-B-C, Waiting Time (Staytime) of orders in the queue, and the daily throughput.
The creation of the orders and the collection of KPI labels in the end are all done in Process Flow.
Loading of the orders to the machine is done mainly in 3D Model and I tried 4 different ways (cases) :
Case 1 : The flow is based on the 3D Model Object connection which flows naturally from the start. Not involving process flow to manage the operator.
Case 2 : Process flow (task sequence) and list is used to load the arriving orders directly to the machine
Case 3 : Same as Case 2 but the operator unloaded the order to another queue before the machine instead of directly to the machine (double queues are used here)
Case 4 : Same as case 1 but the downtime behavior for the machine when off shift is set to Stop and Resume Input instead of Stop and Resume Object
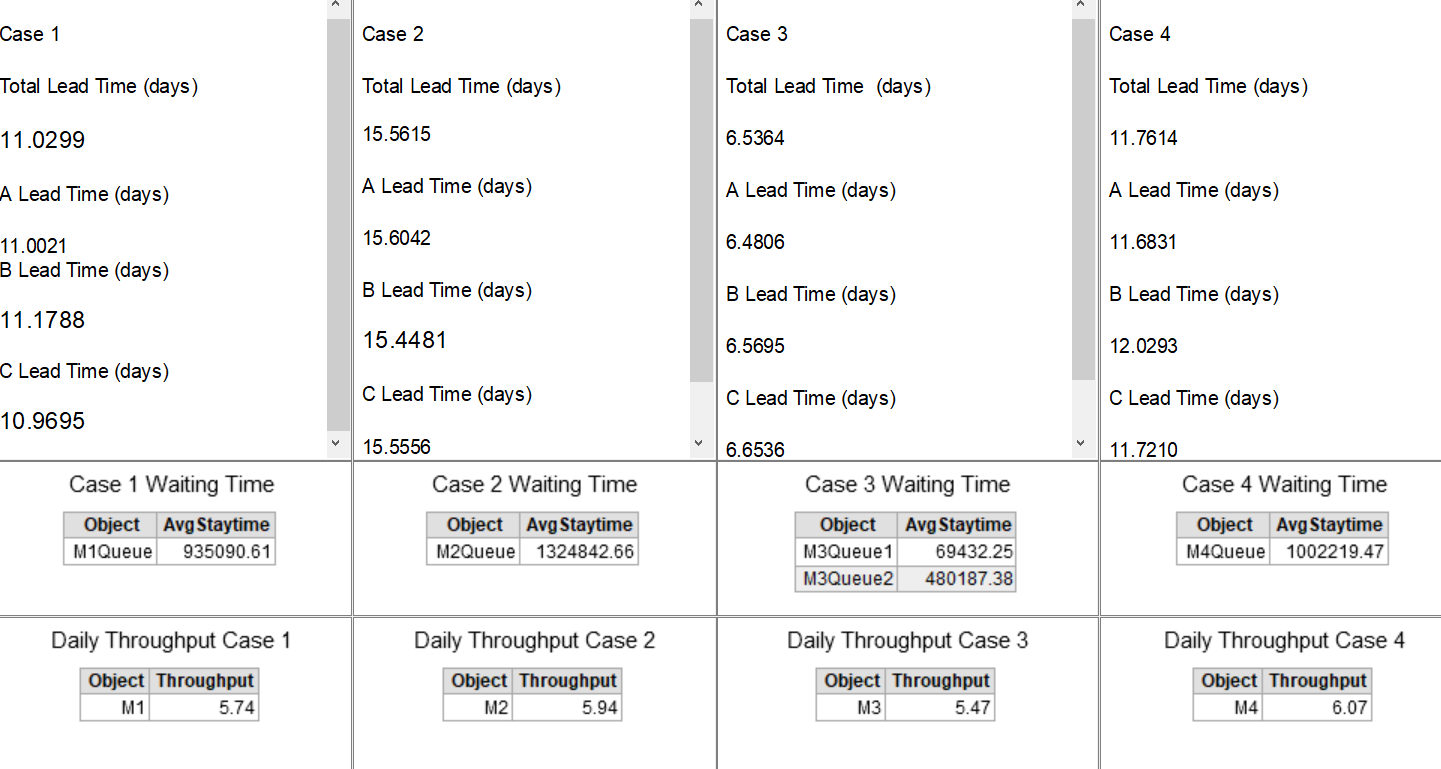
When I run the model all of the cases give quite different results as can be seen on the dashboard output sample below (especially for the stay time), whereas I expect more or less similar results for all 4 cases.
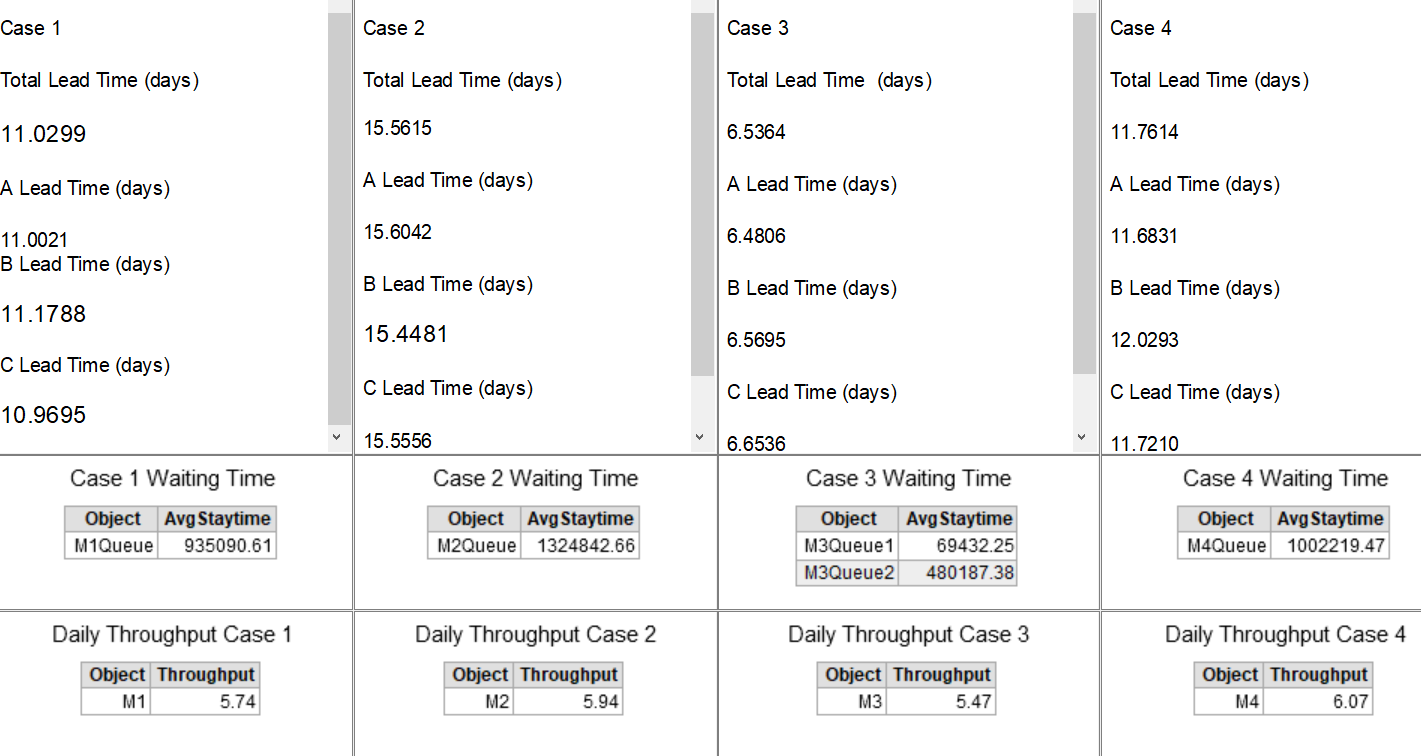
My main question is why the stay time results are very different and which case is the most accurate (or maybe there are other approaches) ? Or is there any assumptions or setting that I did wrong? accurate waiting time is the most important KPI for this model that will also affect the lead time.
Also in relation to case no 4, I still don't quite understand the difference between stop/resume object and stop/resume input(and or output) for the downtime behavior, because the result difference is quite large between them.
I attach here the model to be checked.
Thank you beforehand and sorry if the model is not very well made (still newbie in Flexsim).
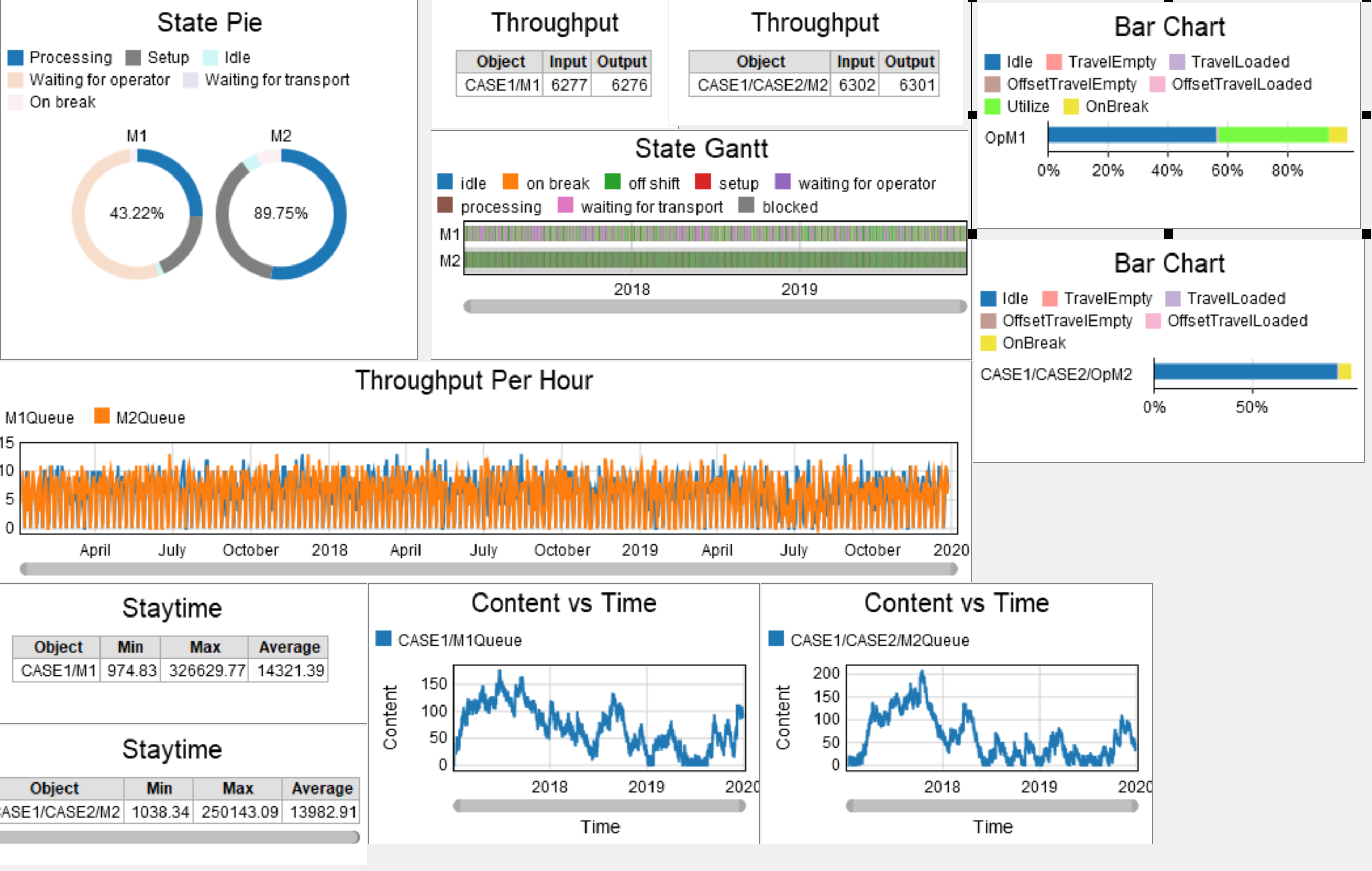
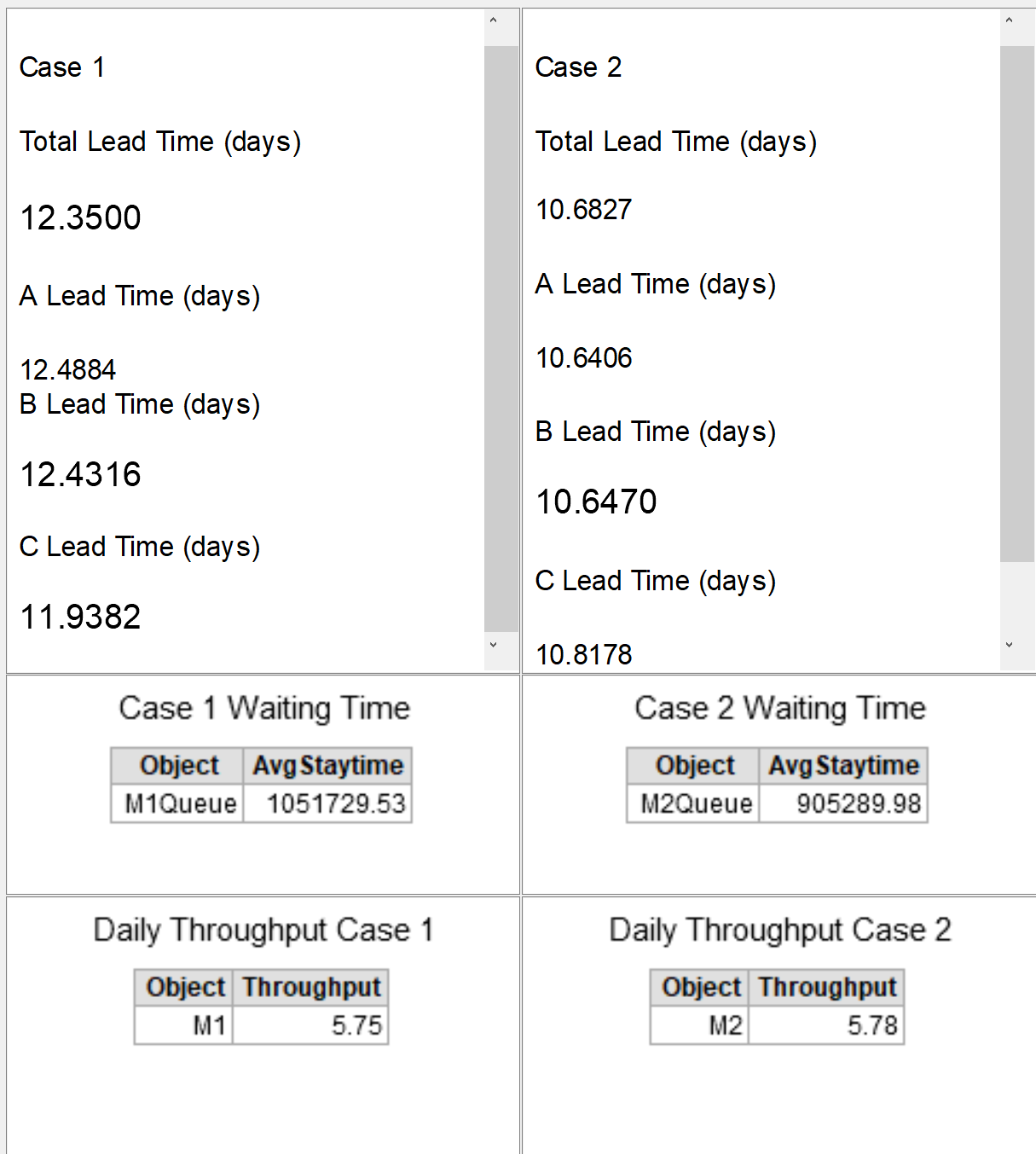


 I only changed the unload destination from the processor to additional queue before the processor (like in case 3) and this was the result.
I only changed the unload destination from the processor to additional queue before the processor (like in case 3) and this was the result.
{kind=link}