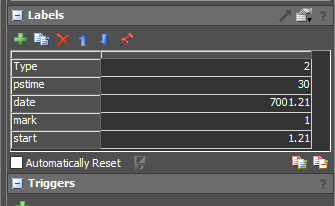
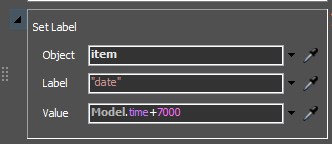
0926.fsmThere are some problems with the reward function. When I add the penalty, there seems to be a problem with the calculation of reward in the env file.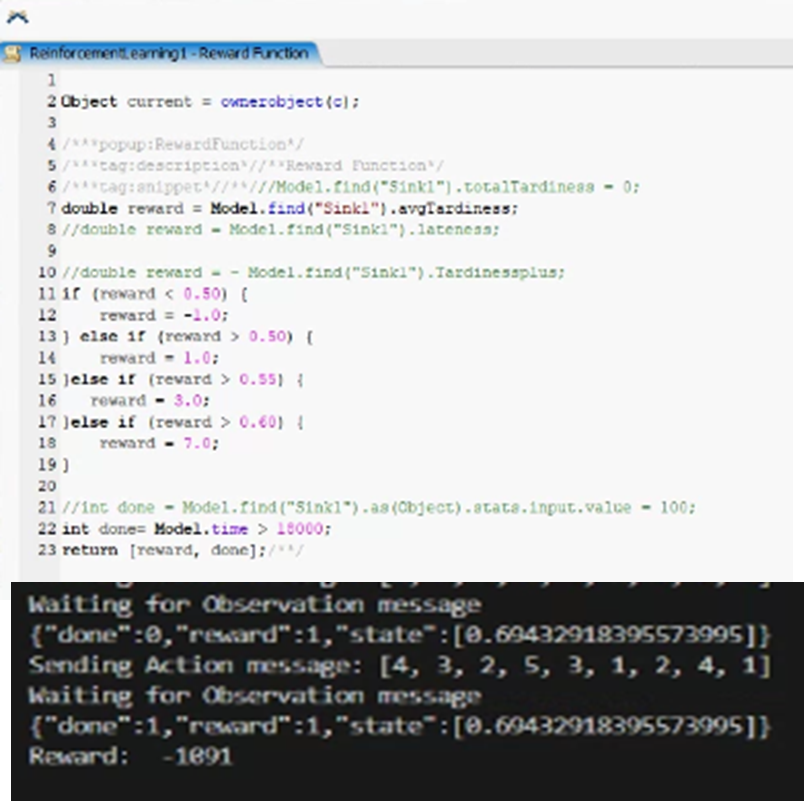
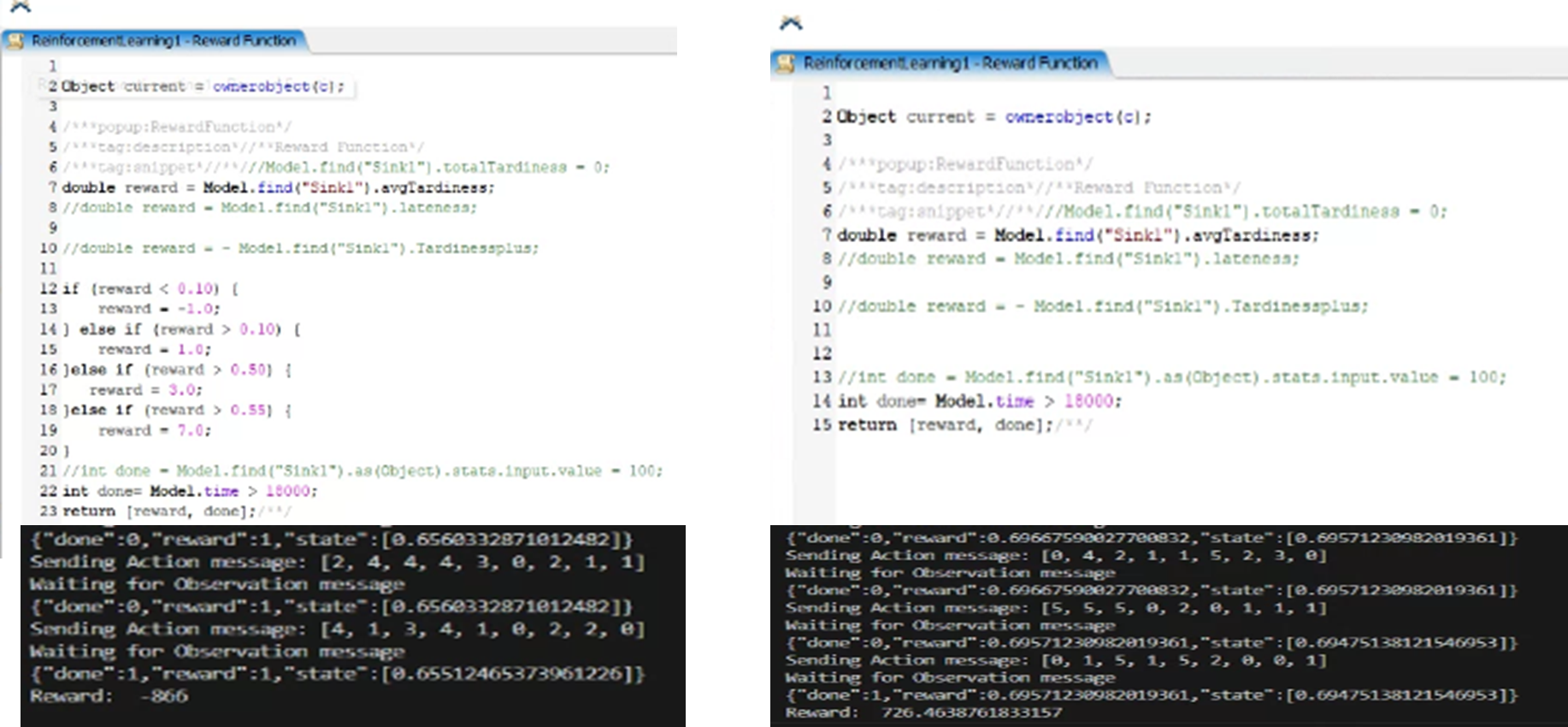
I added a penalty to my reward function, but I think my reward should not be a negative value because even if it is less than 0.1, there will still be a lot of negative values. The last problem is that there is something wrong with my warm up calculation process, warm up will not reset the calculation of custom labels as well.