Hello,
I have worked with your training model:
Flexsim training model, 100.000 timesteps:
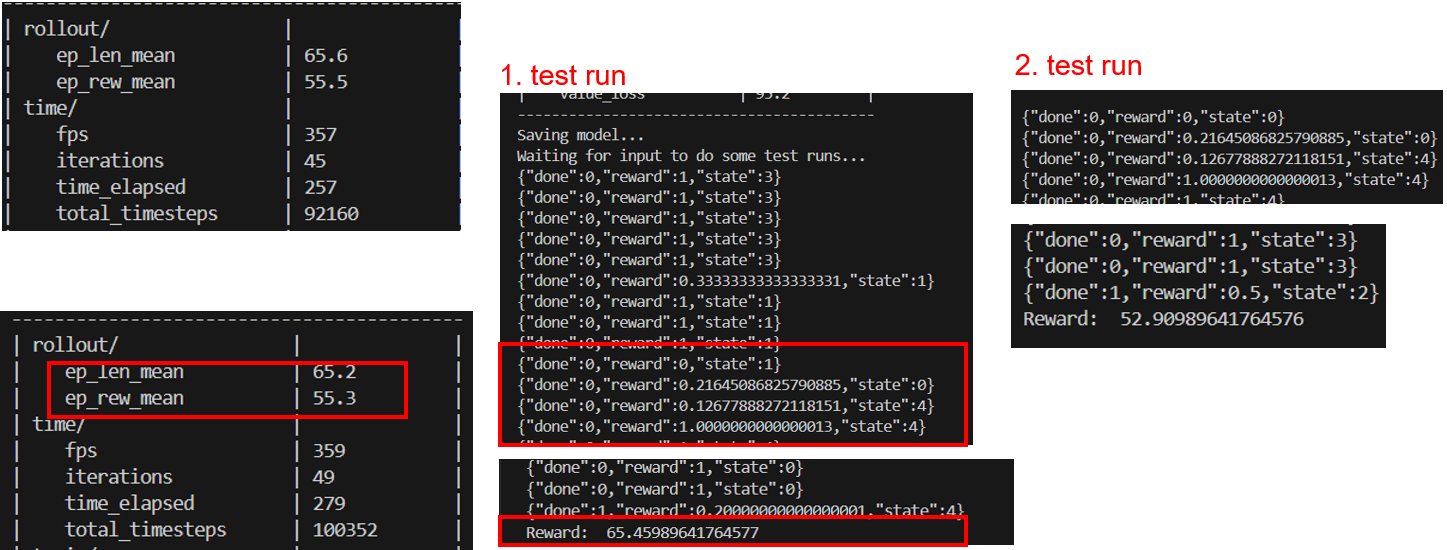
Flexsim_training.py: I have concern regarding the reward 0 and three strange rewards after it and too high overall reward after the 1st test run (it happens similar also by my modified Flexsim models which I have created from yours). The 2nd test run has the 0 in the beginning, but the overall reward seems ok.
But it seems, the algorithm is trained well, when I use the flexsim_inference.py after, it works fine. So are these strange rewards by test runs a problem, or can we use it, as it is? What is a cause of these strange rewards?
Thank you