Hello,
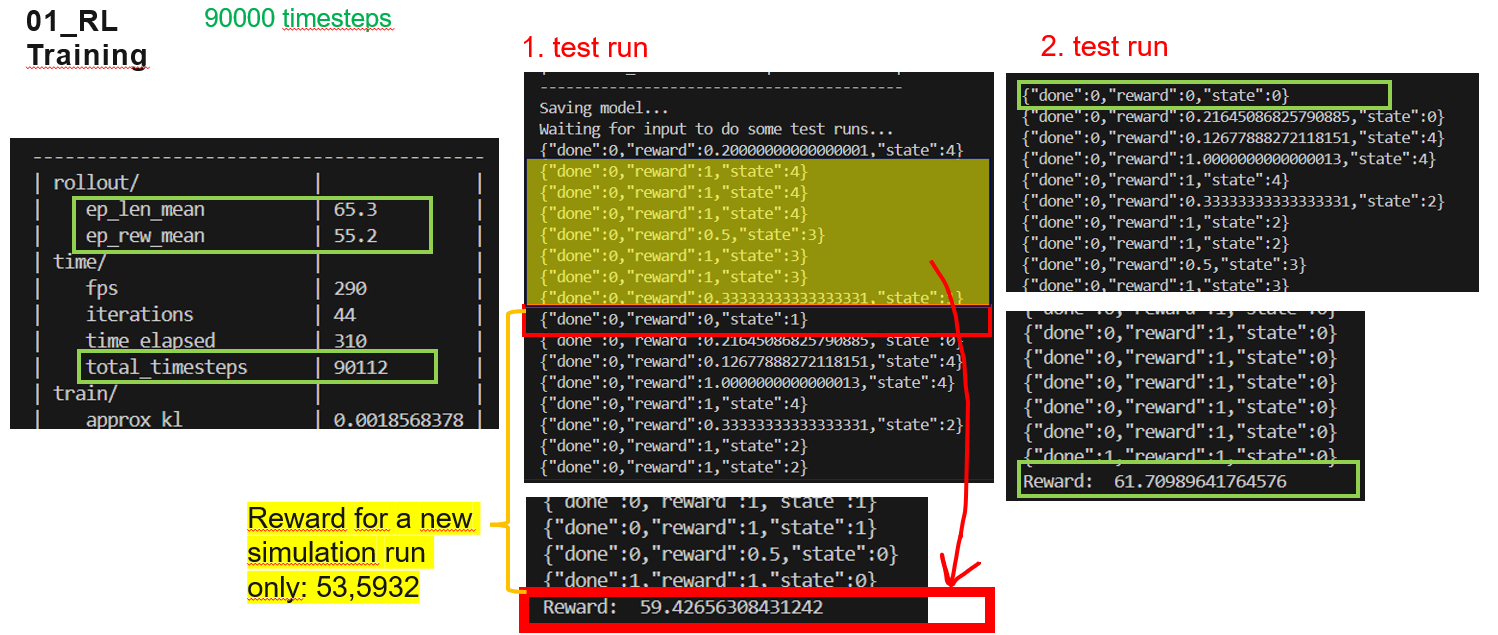
I am using your RL training model. By running flexsim_training.py the "0" appears " after a few rows. It happens in my other similar models too. I have added a print command to the flexsim model: rewards and model reset - so we can see the reward "0" in python corresponds with reset of the model.
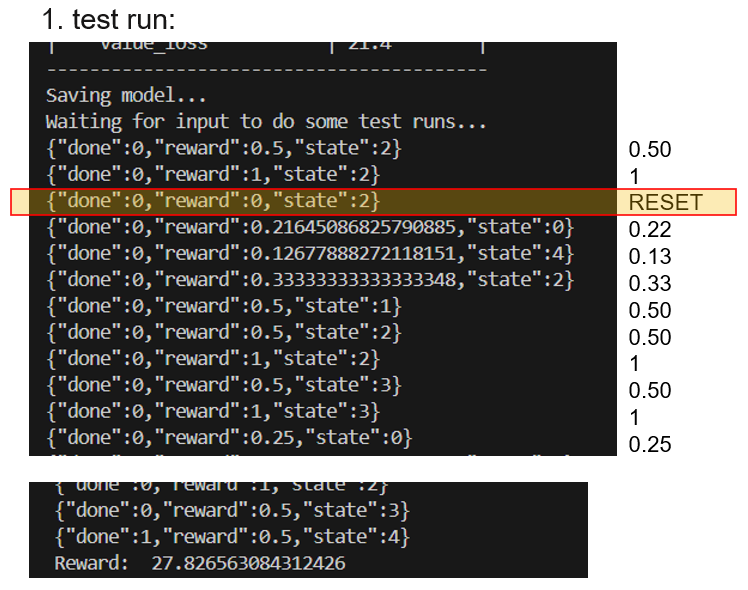
In this situation, the rewards before "0" (it means from the previous simulation run) are counted also into the overall reward of the 1st test run, so this reward is then too high.
Why it behaves like that? Is this a problem or just a "cosmetic issue"?
(The algorithm seems to be trianed well, when using later the flexsim_inference.py.)
Thank you in advance :-)