Dear all,
Please find my model attached.
Following this question.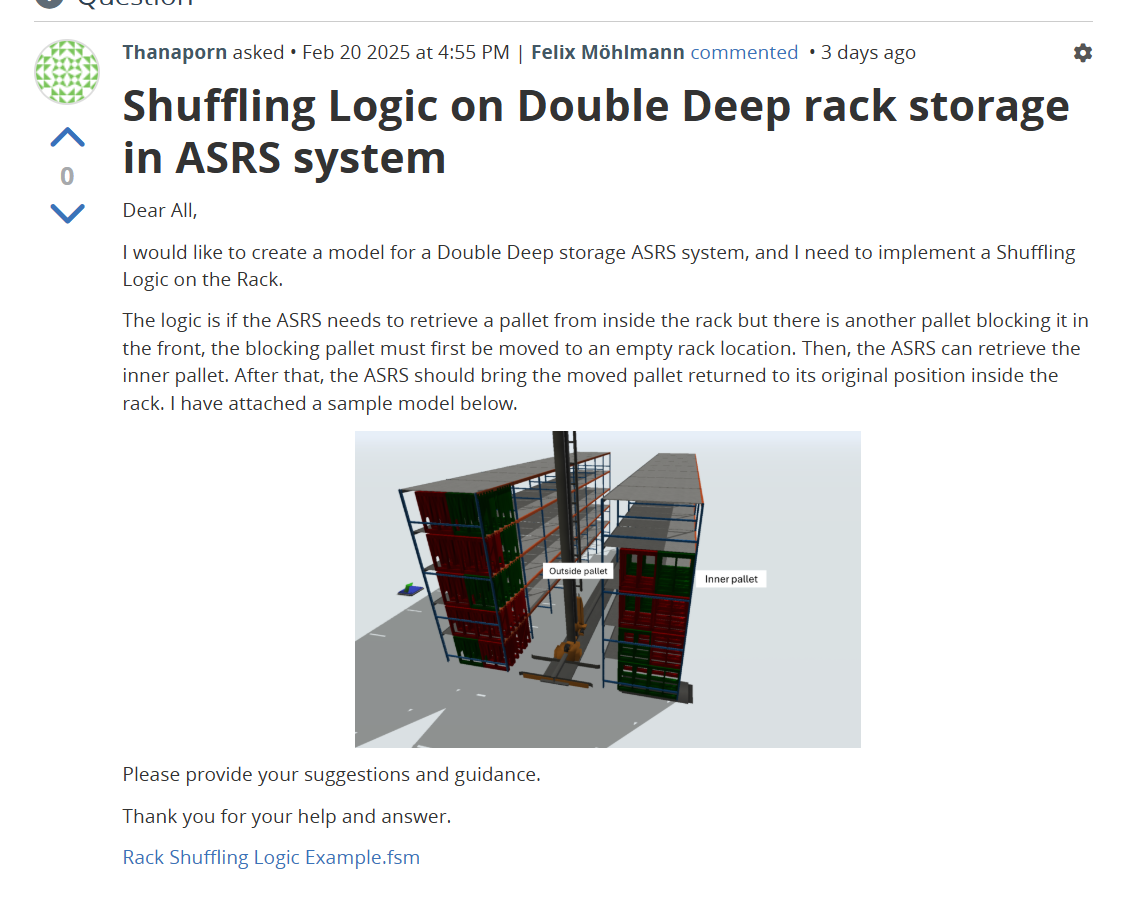
I created an ASRS double-deep storage model with five stacker cranes. I have implemented a shuffling logic for each crane, but the issue is that they shuffle every pallet before retrieving the required one. I want to measure the ASRS throughput per hour by analyzing the number of pallets in the In and Out queues based on the real situation.
Please find my model attached.
ASRS Double Deep Storage model.fsm
My required is
I want the ASRS to retrieve 2 orders per hour.
- Each order consists of 11 SKUs and 67 pallets.
- The ASRS should randomly retrieve around 27 pallets per crane per order.
- Additionally, I have three ABC classification types, where Type 1 has the highest probability of being picked, while Type 3 is rarely or never picked per order.
At time 0, when I initialize the storage, the process takes a very long time. Could you suggest a way to reduce the setup time for the initial stock while maintaining the following logic?
- The same SKU should be stored in the same bay.
- Once a bay is full, other SKUs can be placed in any available empty bay, but SKUs should still be grouped together as much as possible.
- I also have another inbound process for new pallets. Can I apply the same logic to ensure that new pallets of the same SKU are stored in the same bay?
I apologize for posting multiple times, but I have genuinely tried to find the answer. I would really appreciate your guidance.
I believe that if I found a solution for this model will allow me to apply and expand it to many other models in the future.
Thank you for your answer.
