Hi all,
I am currently busy with a project where I must determine the amount of resources that have to be allocated to each step in a process to optimise output/throughput. I would like to use Optquest for this as there are multiple process steps and thus multiple combinations of the number of resources that can be used at each step. I use the Statistics Collector and Calculated tables to aggregate most of the statistics as it is quite a large Process Flow model and measures such as Time In System and throughput have to be taken at different places in the model.
I have recreated my problem on a smaller scale and attached my model and output. In the attached model parts arrive, they acquire the first resource and are processed before acquiring the second resource and leaving the system. The resources are numeric and the count of the resources are set to the values of Process Flow variables I created. These variables were added in the "Scenarios" tab of the experimenter as well as variables in the "Optimizer Design" tab. In the "Performance Measures" tab of the experimenter I added two measures "throughput" and "TIS" which are gathered from Calculated Tables 1 and 3. The "throughput" performance measure is added as the Objective Function in the "Optimizer and Design" tab and the "Direction" is set to "Maximize".
When I run the Optimizer and "Export as CSV" the results are as seen in the attached "testOpt1" CSV and in the eplanitory picture below. You will see that the column headers do not line up and extra columns are added that I cannot trace to a column header.
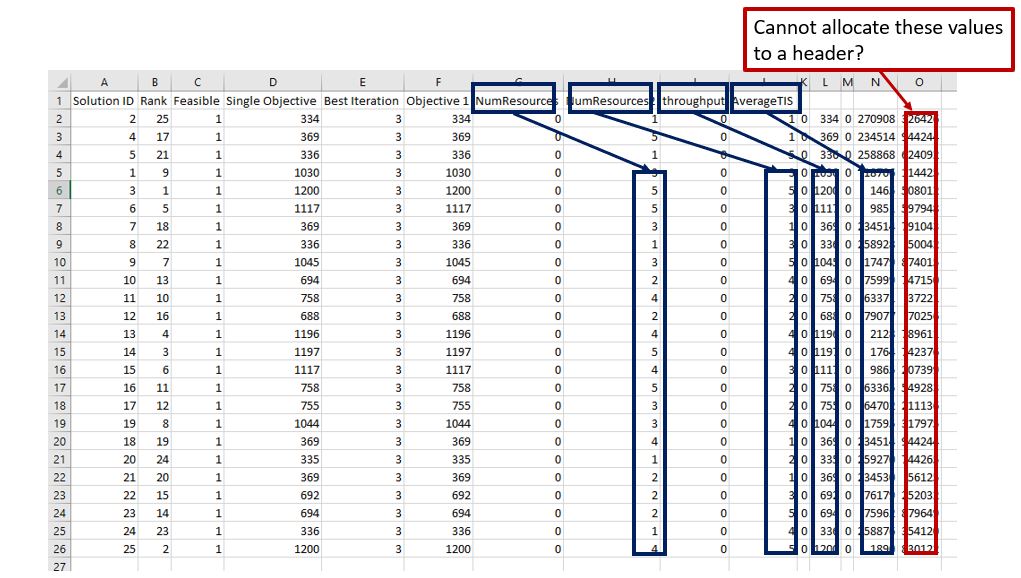
As I mentioned, my model is much larger than the one I attached andtestoptquest.fsmtestopt1.csv I have a lot more variables and performance measures (some of which might/must be zero). It is thus very difficult to see what data belongs to which column. Is there a way I can fix this?
Your help is appreciated.