Hello,
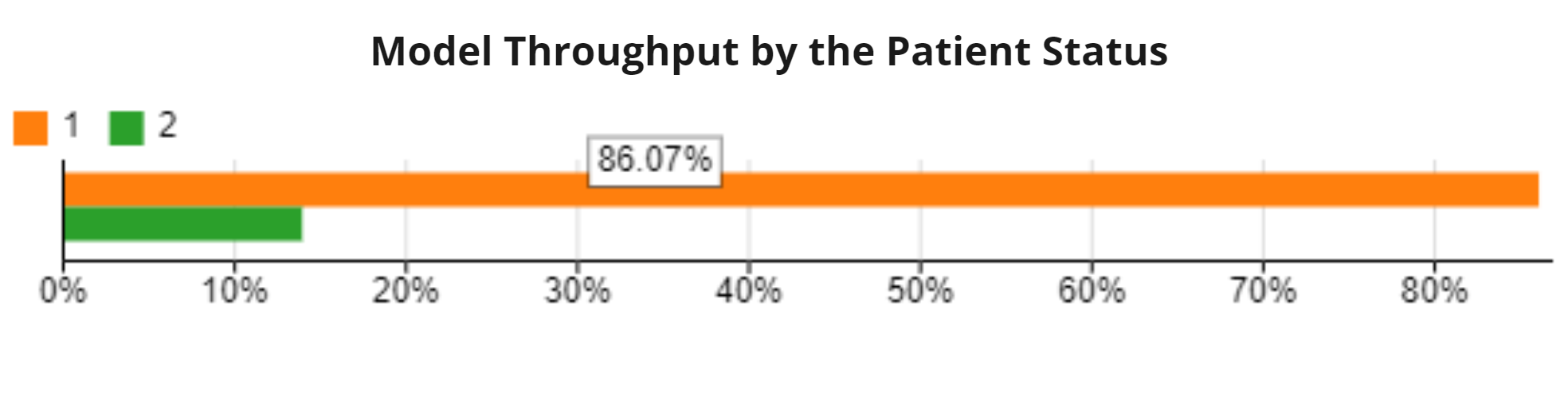
I have several separate patient flows in the model, and for each I labeled 70% of patients to have value X and 30% of them to have value Y under the arrivals tab. Either running the model over replications (25 rep.) or just a single run, when I get the throughput by label (%) I see it is not as I set it (it's more like 15% vs 85% like pic below). Is there any way that I can make it accurate other than importing all labels in Global or Arrival table, or how can I make sure it is labeling based on %?