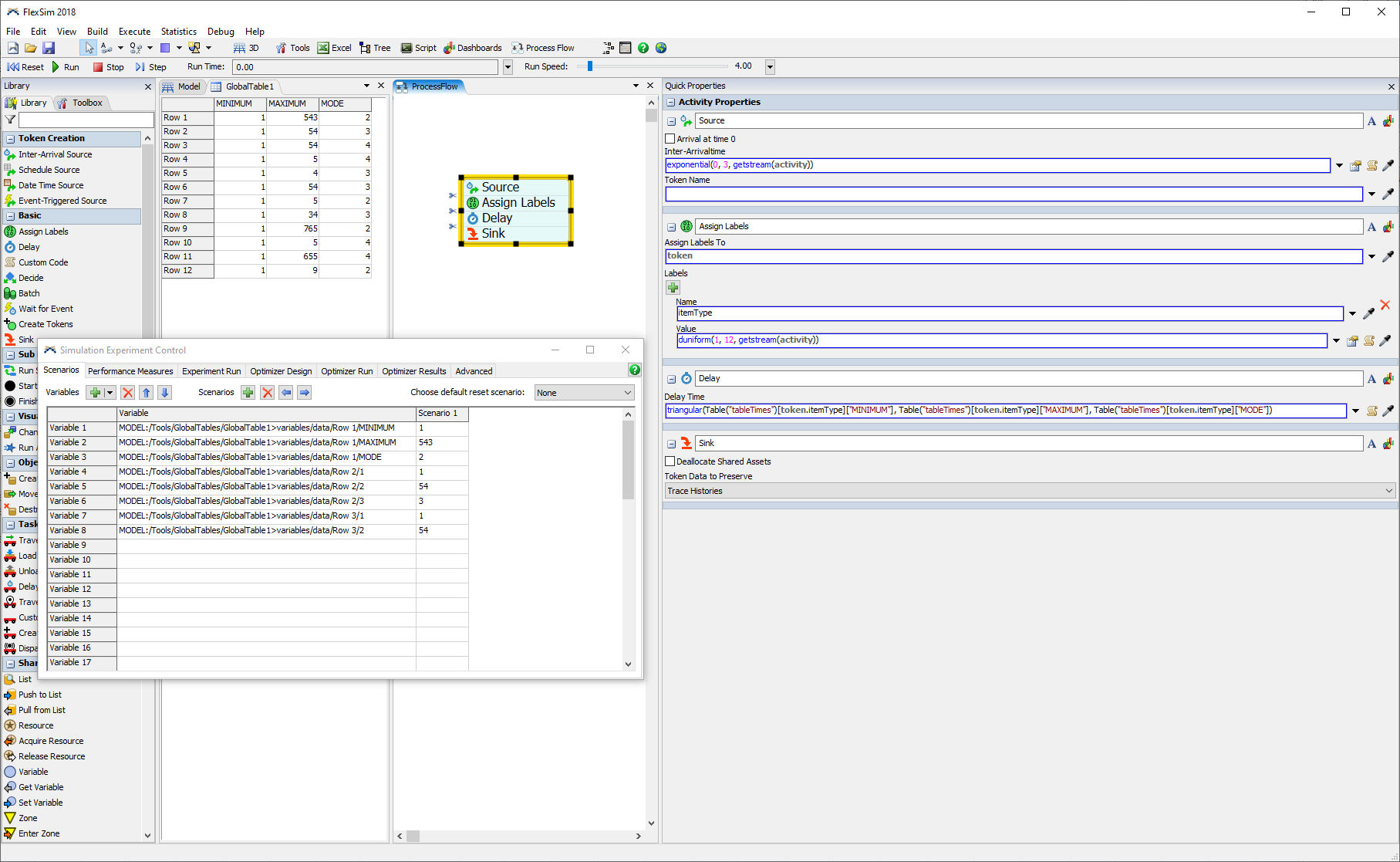
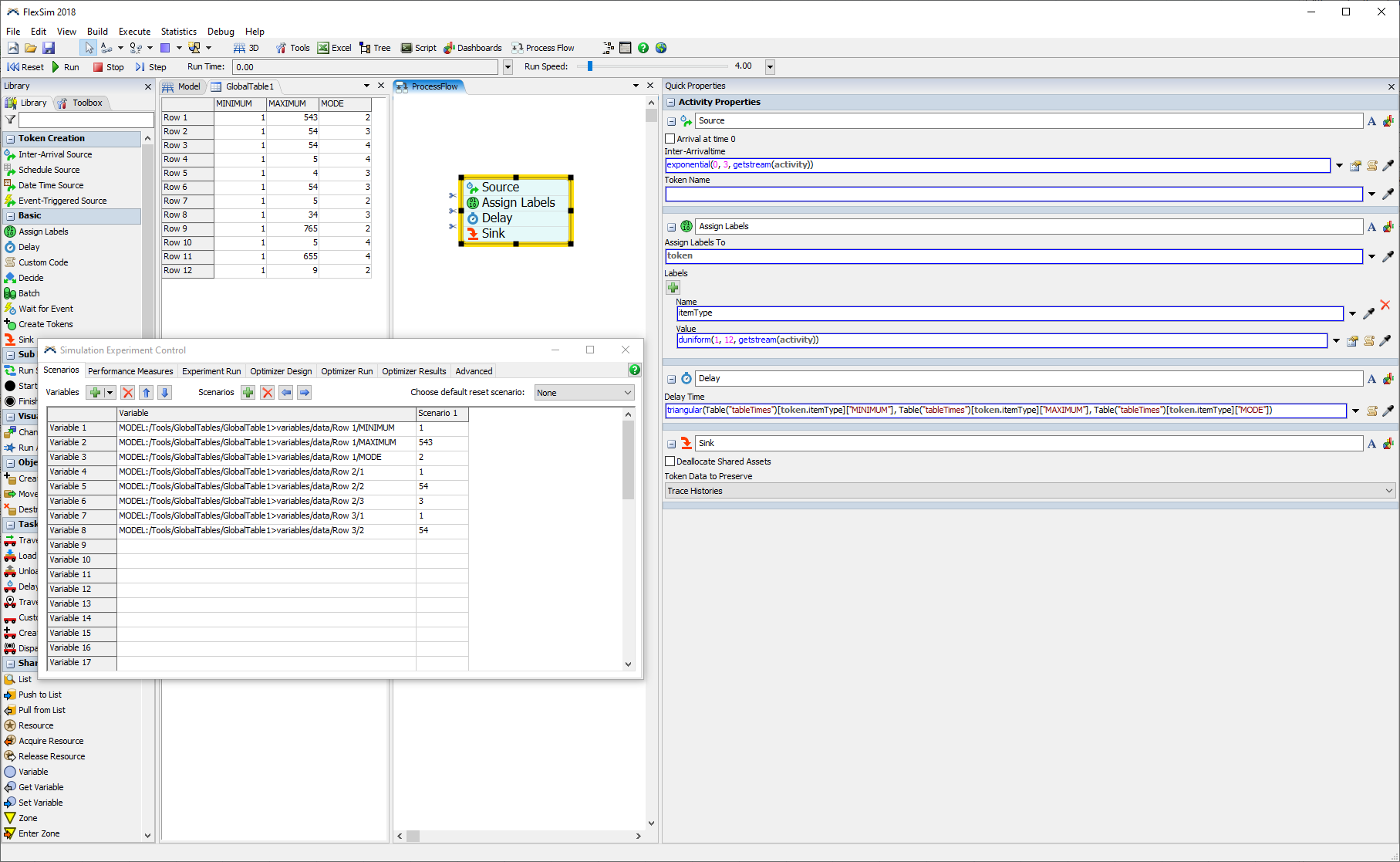
I have some existing models that use dashboard elements (e.g. editable text, table), connected to global tables, to provide inputs to the logic. When I wanted to use the experimenter, I could refer to those same global table cells to create a scenario.
In the new experimenter I have to define a parameter, and I am struggling to understand how to connect the parameter to the global table. For a variety of reasons I do not want to replace the global tables with parameter tables. I am hoping that I have missed something and you can tell me how to use parameters with global tables.
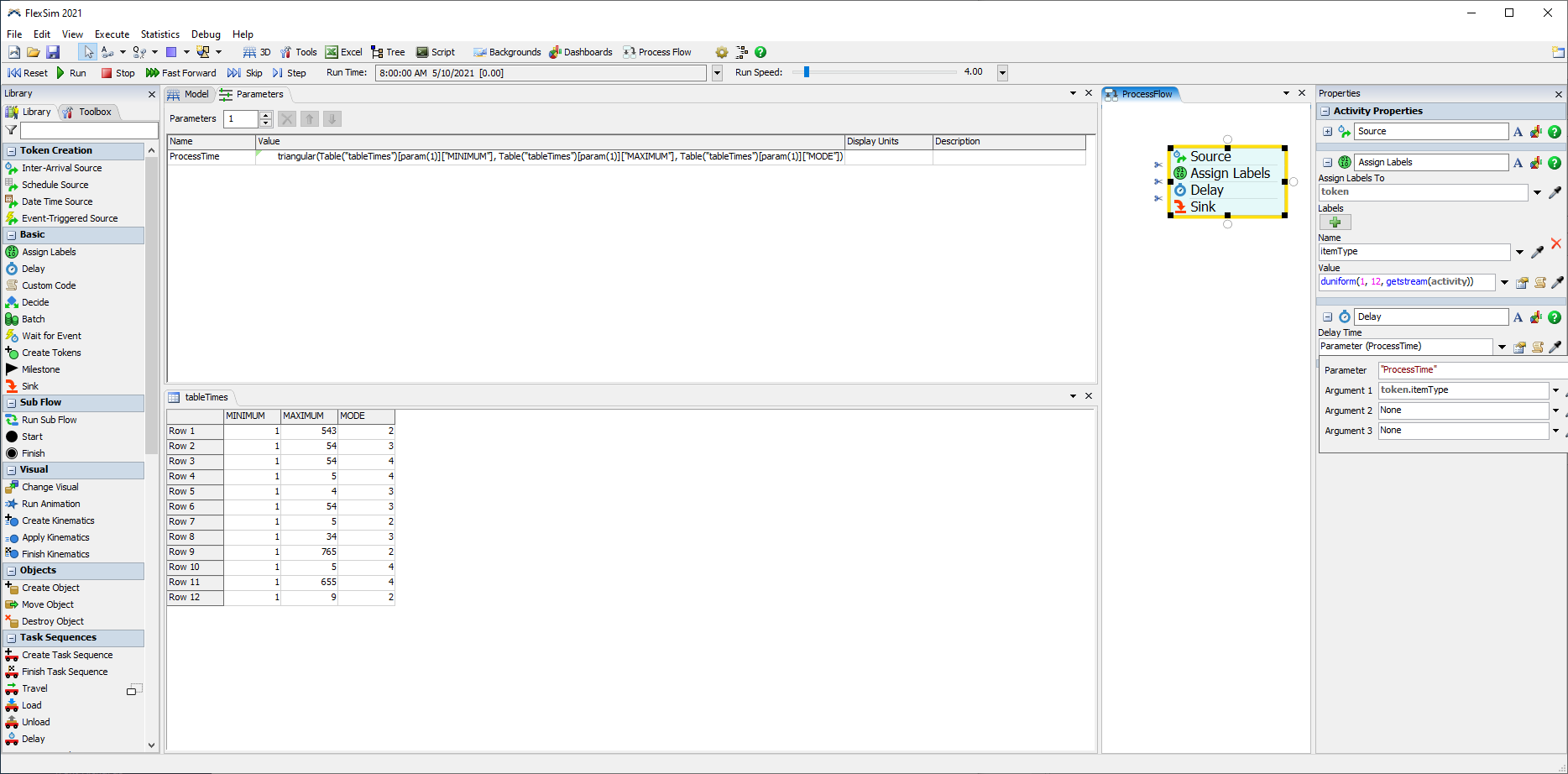

{kind=link}
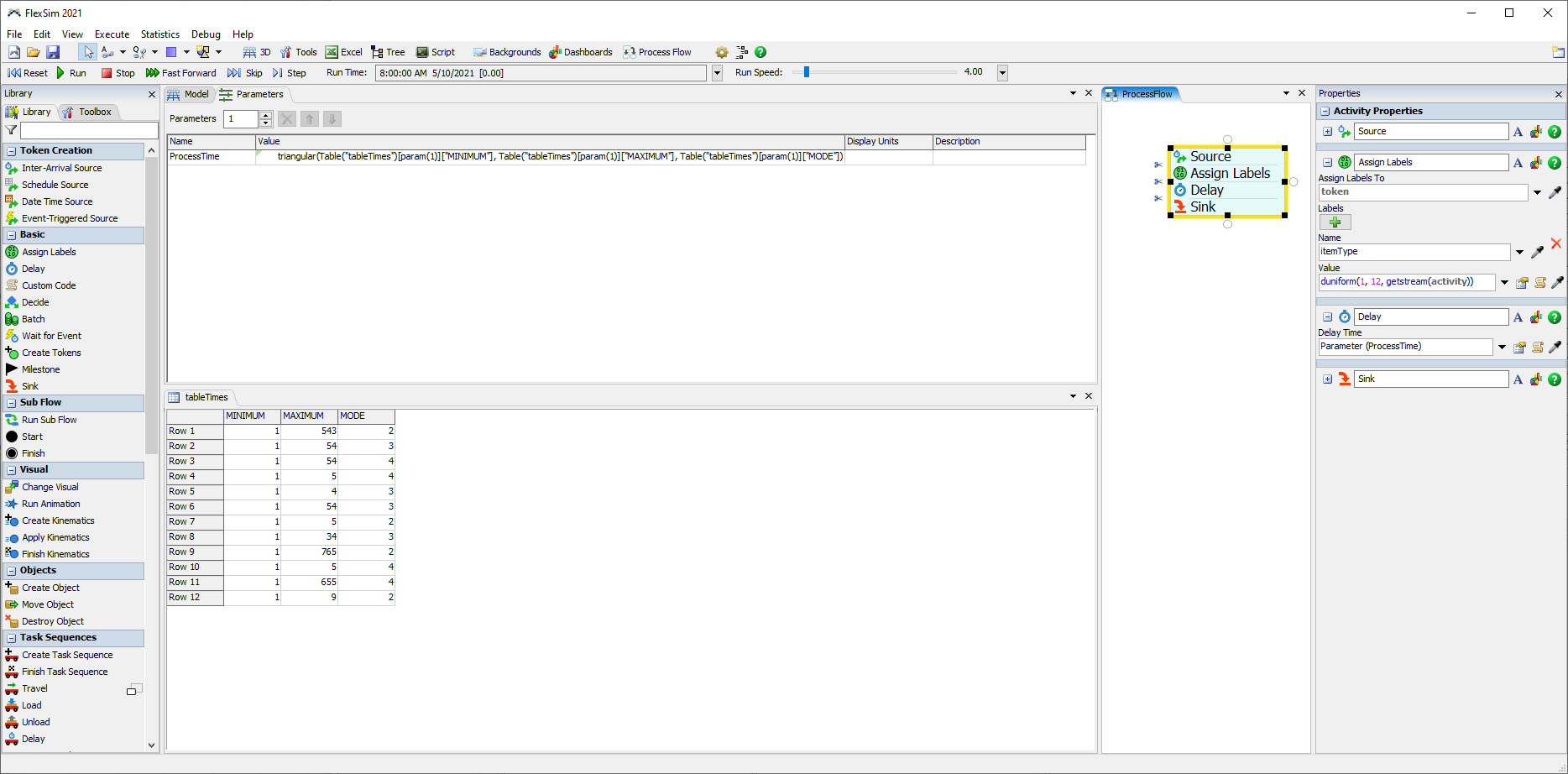{kind=link}
{kind=link}