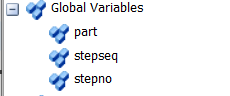
Essentially the title of the question; I have a global table containing the process times of every part number that could possibly run through the facility being modeled. The flow items follow a schedule imported from Excel into the ProcessFlow, thus I created a Custom Code block to change the process time of each machine according to the part number label attached to each token. I've managed to get that bit working, but the added layer of complexity is that there are different steps that correspond to different processing times. Is there some way to have the Global Table lookup first search column 1 to find the correct part number, then search column 2 to match the correct step sequence to then return the correct processing time in column 4?
I cannot post my actual data due to security but it is very similar to this:
| Part Number | Step Sequence | Setup Time | Process Time |
|---|---|---|---|
| 100 | 1 | 43 | 62 |
| 100 | 2 | 46 | 82 |
| 100 | 3 | 21 | 19 |
| 101 | 1 | 13 | 45 |
| 101 | 2 | 26 | 39 |
| 102 | 1 | 15 | 29 |
| 102 | 2 | 23 | 87 |
| 102 | 3 | 14 | 63 |
| 102 | 4 | 28 | 78 |
Currently, the code that works with just looking up using column 1 is this:
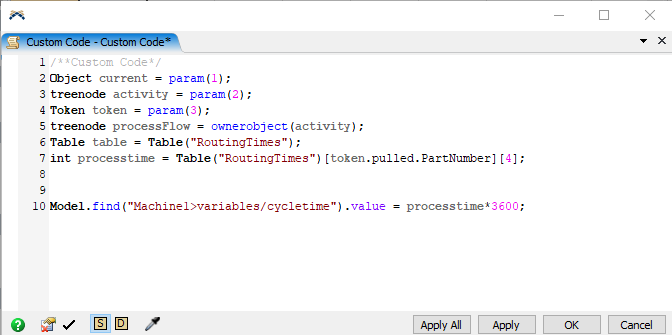
ProcessFlow:
3D Model: