Hi everyone, I have some problems with my model
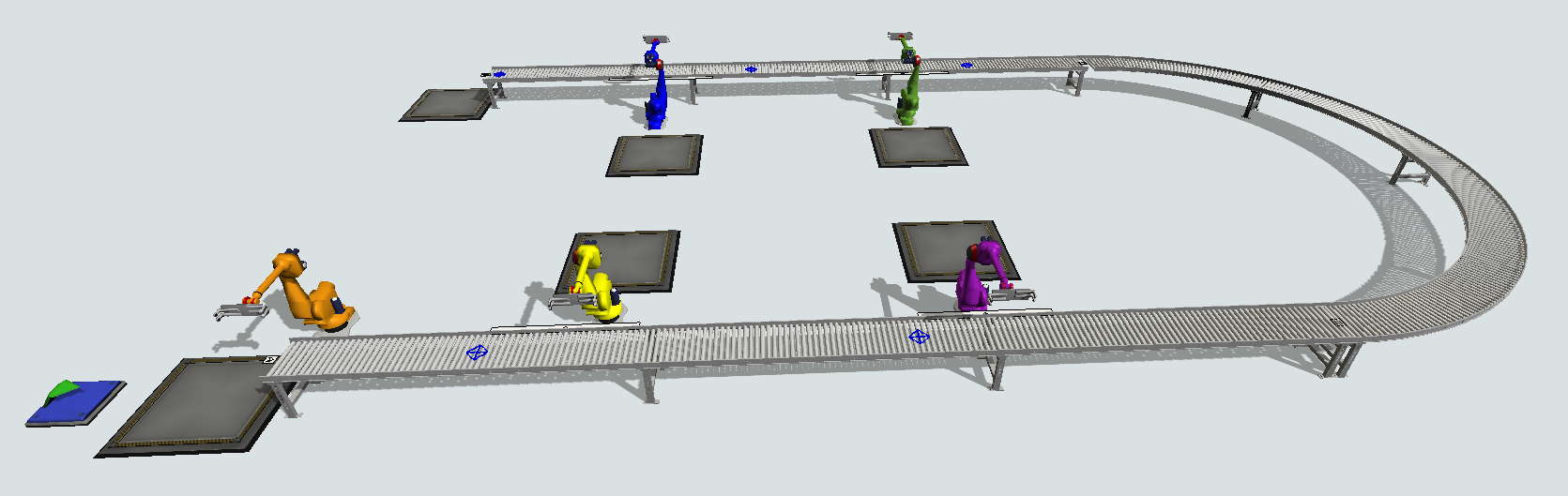
The aim of this model is to train orange robot in order to make it choose correctly what good he has to pick, because there are 4 kinds of goods relating to their color. If the robot is well trained, he will learn to not to pick for example two yellow goods consecutively in a small time, because yellow robot will no have time to pick both of them. So the queue at the end of the conveyor should be empty if everything is working.
Now, I have created two parameters: LostItems (an observation parameter) which count items who enter in the last queue, and ItemType (an action parameter) which represent the 4 kinds of goods.
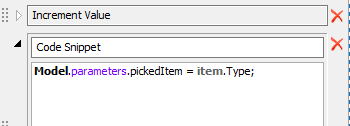
I have created a label called Items on the last queue, and i have set a on entry trigger with increment value which increase Items when goods in the queue.
In the orange robot i have created a label called Reward and i have set an on entry trigger with increment value by 10/(10 + (Model.find("Queue4").Items)) on current.labels["Reward"], so more items enter in the last queue, less would be the reward.
In the RL tool, my observation function is:
Model.parameters["LostItems"].value = Model.find("Queue4").Items;
And my reward function is:
double reward = Model.find("Robot1").Reward;
Model.find("Robot1").Reward = 0;
int done = (Model.time > 1000);
return [reward, done];
When I try to train my model, rewards remain stable and don't increase. I think I am not using well initial parameters.
What do you suggest to do? Here is my file: modello6_5.fsm