Hi!
In the model that I created there is a source that generates two type of element identyfied by a label (and color) defined on the item, 'Type': so the red one is Type 1 and the green one in Type 2.
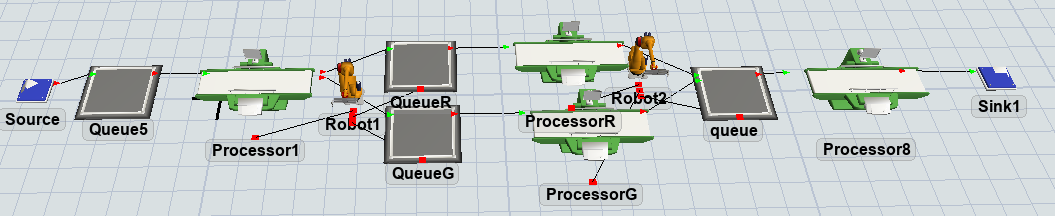
My purpose is to make the robot2 intelligent using the Reinforcement Learning tool: it should take an element depending on the longest queue choosing from the red one or the green one.
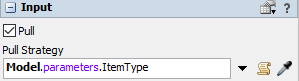
As Observation parameters I used the number of elements in the queues and the ItemType as Action parameters.
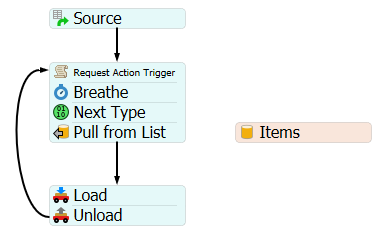
In order to do so I defined a label on the robot2 named 'Reward' and I inserted a trigger On Load>Increment Value then, by modifying this code, I established the value associated with the variable 'reward' depending on the case:
1. When ItemType=1 (so the robot2 chose the red one) the reward must be 100 if the number of elements in the red queue is greater than the number in the green one, otherwise the reward must be -100.
2. When ItemType=2 (so the robot2 chose the green one) the reward must be 100 if the number of elements in the green queue is greater than the number in the red one, otherwise the reward must be -100.
Is the code for the reward label exact? Is the Reward Function in the RL tool exact (is the done criteria correct?) ? Is correct not to have a pull strategy defined on the robot (so it only learns by reawards)? How many total_timesteps should I insert in the training script? 1000s is too little?
The main problem is that the robot2 doesn't become intelligent due to:
a) It continues loading and unloading items randomly (it takes first a red and then a green item continuisly)
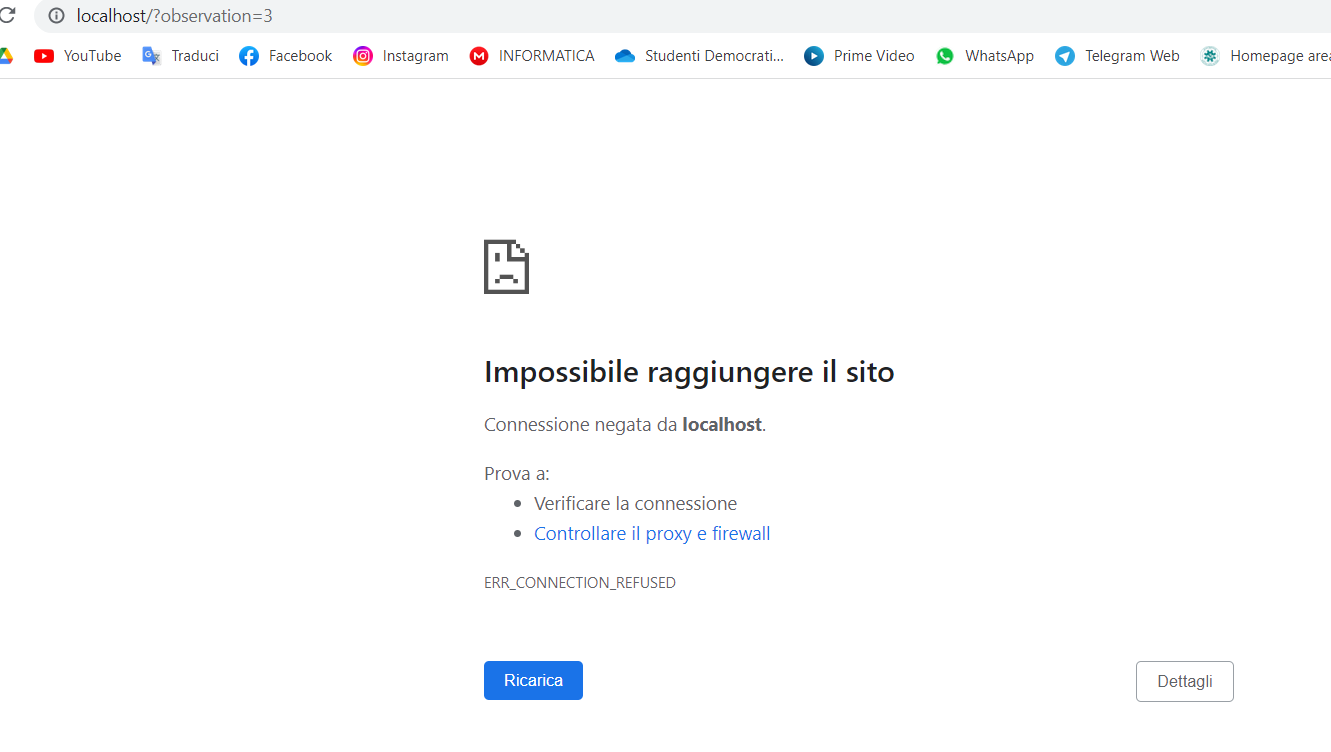
b) In the scripts given by FlexSim, the connection to the local host in the inference script is broken (so basically I'm stucked at step 4 of this guideline https://docs.flexsim.com/en/22.1/ModelLogic/ReinforcementLearning/UsingATrainedModel/UsingATrainedModel.html )
I'm uploading my model here, please check it in order to have a full view.
Can someone please help? I'm going crazy... there are very fiew examples on RL resolutions.